

ミムチはWebサイトの情報を自動取得したいのですが、どちらを使えばよいかわかりませんぞ…

まずはクラウドフローと、デスクトップフローの仕組みの違いを説明するね!
この記事では、Power Automate(クラウドフロー)と、Power Automate Desktop(デスクトップフロー)の基本的な仕組みの違いを解説し、簡単なWebスクレイピングのフローを実装する方法を紹介します。
- Power Automateのクラウドフローと、デスクトップフローの仕組みの違い
- Power Automate Desktopでフローを作る手順
- Power Automate DesktopでWebスクレイピングをする方法
Youtube動画で見たい方は、こちらからどうぞ!
Power Automate Desktop(RPA)の基本的な仕組み
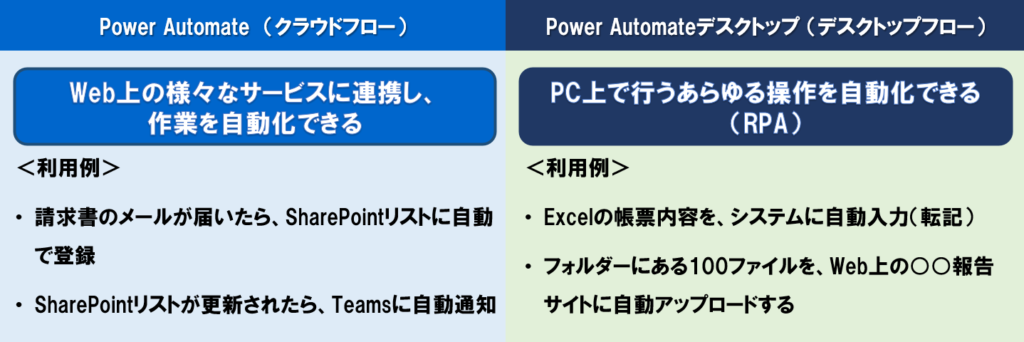
はじめに、Power Automate(クラウドフロー)とPower Automate Desktop(デスクトップフロー)の違いを説明します。

2つには、以下のような違いがありますな。
Power Automate Desktopとは何か?を知りたい方は、以下の記事も参考にしてください。

前回は表面的にできることの違いだけ説明したけど、今回はもう少しそれぞれの仕組みについて深堀りするね!
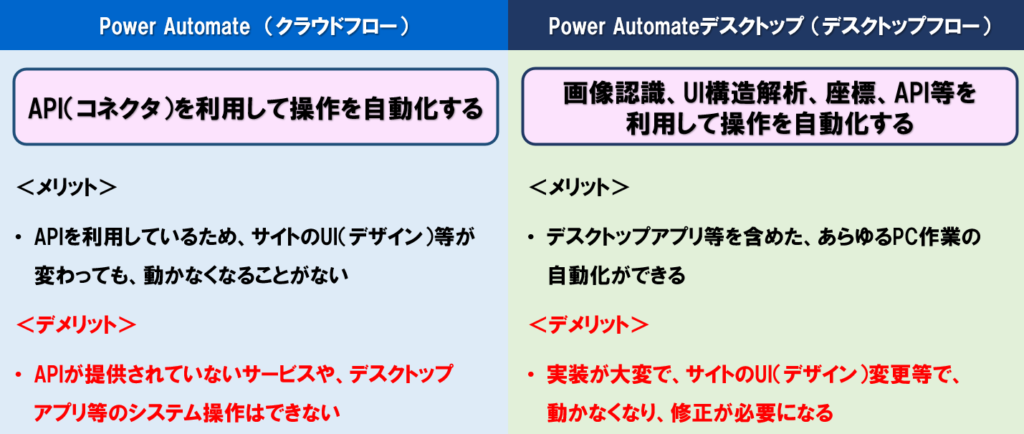
2つの仕組みの違いを簡単にいうと、Power Automateは、APIを利用して操作を自動化するもので、Power Automate Desktopは、画像認識やUI構造解析、座標、API等を利用して操作を自動化します。
APIとは、各サービスが提供している、外部とやり取りをするための窓口で、Micoroftや、Amazon、Googleをはじめ、様々なサービスでAPIが提供されています。
Power Automateは、「コネクタ」という各サービスのAPIを簡単に使える仕組みを利用して、操作を自動化しています。

そのためPower Automateでは、APIが提供されていないサービスや、デスクトップアプリ等のシステムは操作できないデメリットがありますが、RPAのようにサイトのデザインが変わったら動かなくなるということはありません。
一方で、Power Automate DesktopはRPAなので、画像認識、UI構造解析、座標、API等を利用して、操作を自動化しています。
そのためデスクトップアプリ等を含め、あらゆるPC作業の自動化ができますが、Power Automateより実装が大変で、サイトのデザインが変更されると動かなくなる等メンテナンスが必要になります。
RPAで、例えばWebサイトから情報を取得する場合、以下のようなHTMLのDOMツリー等を解析し、情報を取得しています。
HTMLや、XML等の階層構造を頑張って解析して、記事のタイトルや入力ボックスボタン等を判別して、操作を行っているわけだね。
簡単に両者の違いを比較すると、以下のようになります。

Power Automate Desktopの方が、Power Automateに比べて実装が大変で、修正が必要な頻度も高くなります。
Power Automate Desktop等、RPAを使うのは、APIが提供されていないシステムの自動化など、他のツールで実現できない場合の最終手段と考えて良いかもしれません。
プログラミングの基本処理「順次」 「分岐」 「反復」とは?
次に前提知識として、プログラミングの基本の3つの処理、順次、分岐、反復について復習します。
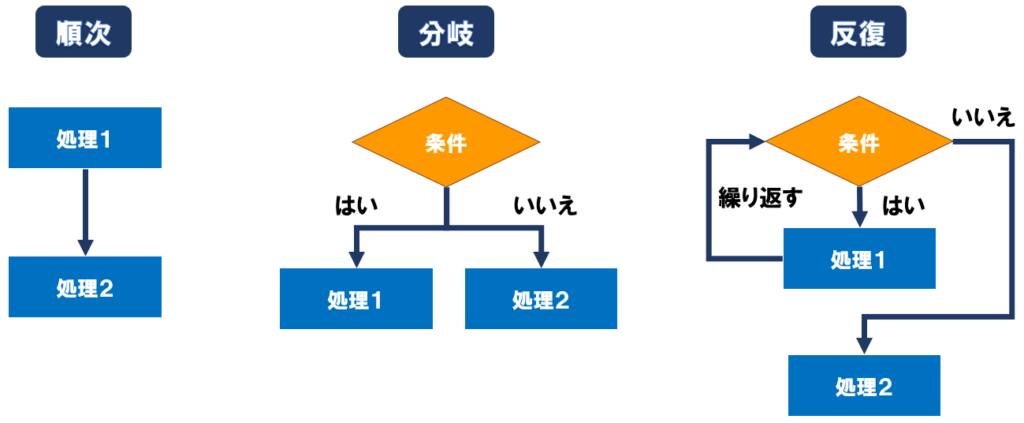
RPAでフローを作る際の基本的な処理は、この3つになります。
この基本の3つの処理については、以前の記事でも解説していますので、復習したい方は参考にしてください。

Power AutomateもPower Automate Desktopも基本的にこの3つの処理の組み合わせになりますので、是非覚えておきましょう!
変数とデータ型
次にRPA開発に必要な知識となる、変数とデータ型について解説します。
変数とは?
「変数」とは値を一時的に格納しておく箱のようなもので、後から取り出したり、更新したり、計算等をしたりすることができます。
例えば以下のようなフローを作るとします。
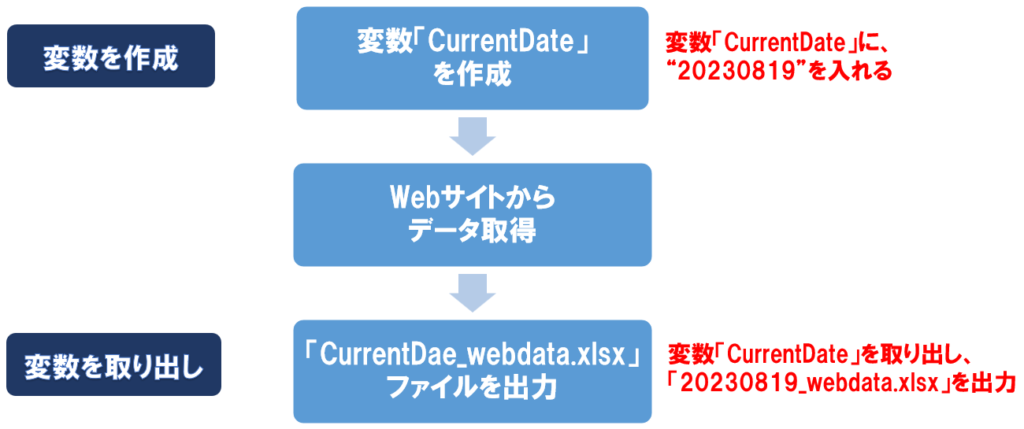
最初に「CurrentDate」という名前の変数を作成し、”20230819″という値を入れます。
そしてWebサイトからデータを取得した後、そのデータをExcelに吐き出し、「20230819_Webdata.xlsx」というファイルで出力する、といった感じで使うことができます。
これは作成した変数「CurrentDate」(”20230819″)をそのまま取り出して使う例ですが、変数が数値データの場合は、計算等をすることもできます。
以下は実際のPower Automate Desktopの編集画面です。
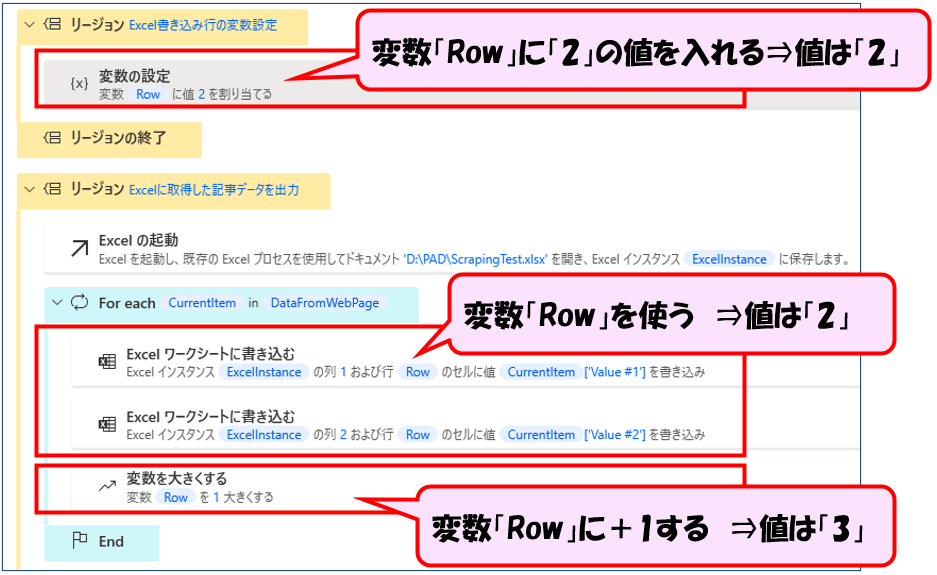
このフローでは、以下のような処理をしています。
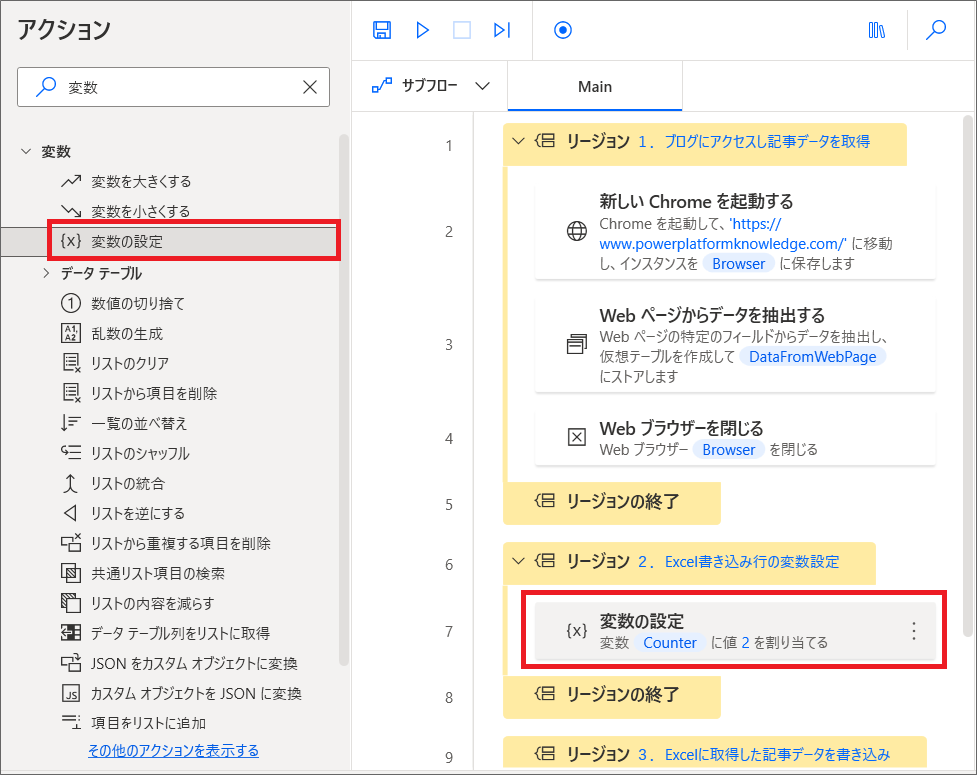
- 変数の設定アクションで、「Row」という変数に2という値を入れる
- Webから取得したデータをループ処理(For Each)を使って、1行ずつExcelワークシートに書き込むアクションを追加する。
※この時変数「Row」を使い、最初はExcelの2行目に取得したデータを書き込む - ループの最後で、変数「Row」に+1をして、変数「Row」の値は3になる
- 次のループ処理に入った時、「Row」の値を取り出し、Excelの3行目にデータが書き込まれる
このように変数が数値データである場合、四則演算と数値同士の計算ができます。
もしこの変数Rowに入っている値が、”りんご”等の文字列データである場合は、当然計算ができません。
データ型とは?
データ型とは、その値が数値なのか、テキストなのか等、どのような種類のデータ化を定義するものです。
Power Automate Desktopでは主に、以下の表にある5つのデータ型があります。
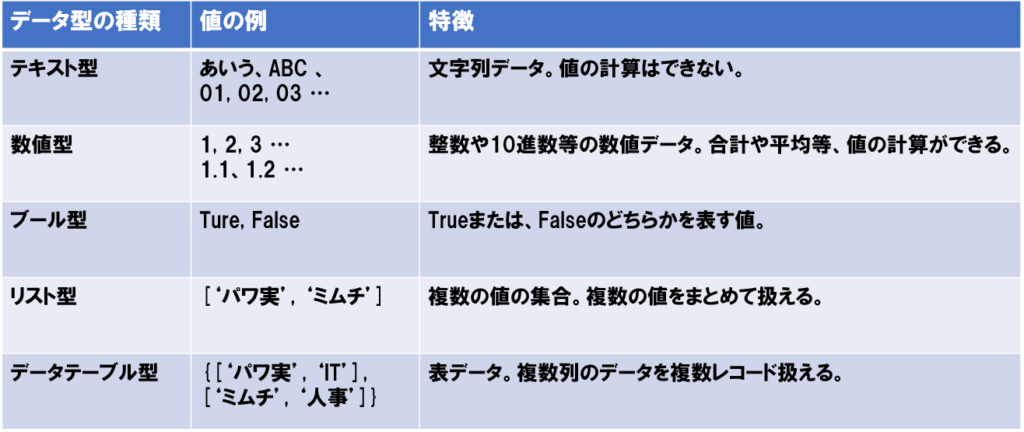
リスト型や、データテーブル型のデータは、ループ処理で、順番に1行ずつ列ごとに値を取得することができます。
Power Automate Desktopは主に、これら5つのデータ型を使うことができますので、是非覚えておきましょう。
Webサイトの記事情報を取得するフローを作る!
それでは実際にWebサイトの記事情報を取得するフローを作ってみましょう!
フロー作成の手順
最初に簡単に作成するフローの流れを整理して、リージョン分けておくと作りやすくなります。
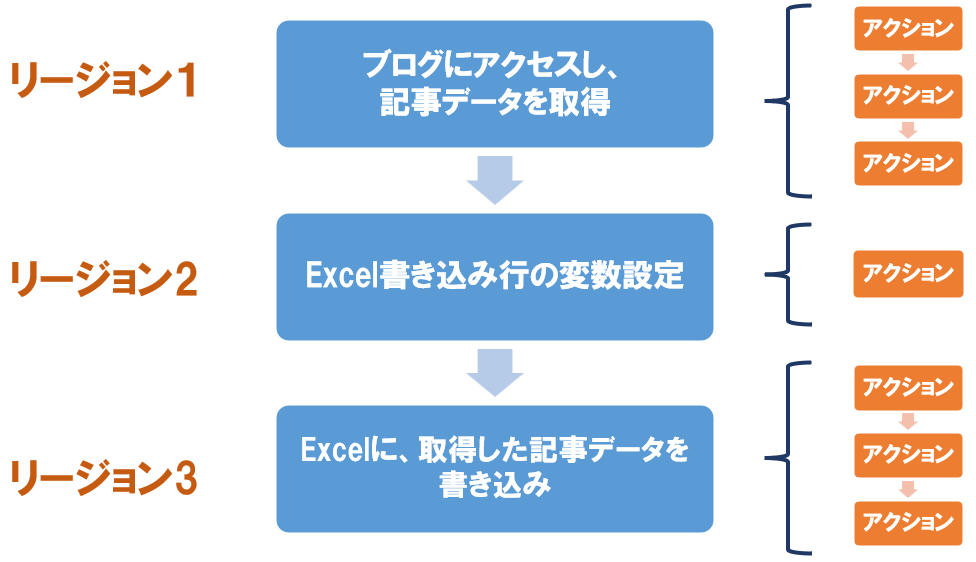
今回のフローでは、上記のように3つのリージョンに分けました。
リージョンとは、複数のアクションをまとめておけるPADの機能の一つです。
フローを作る
1.Power Automate Desktopの編集画面を開きます。
2.アクションからリージョンを検索し、真ん中にドラッグ&ドロップをし、以下の3つのリージョンを作成します。
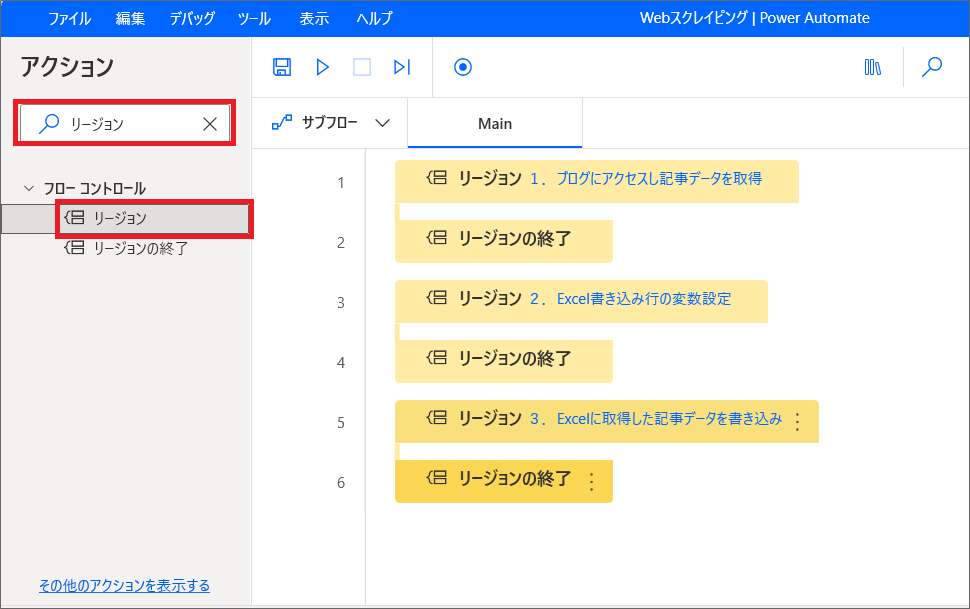
- ブログにアクセスし記事データを取得
- Excel書き込み行の変数設定
- Excelに取得した記事データを書き込み
次にリージョンの中に、アクションを追加していきます。
1.ブログにアクセスし記事データを取得
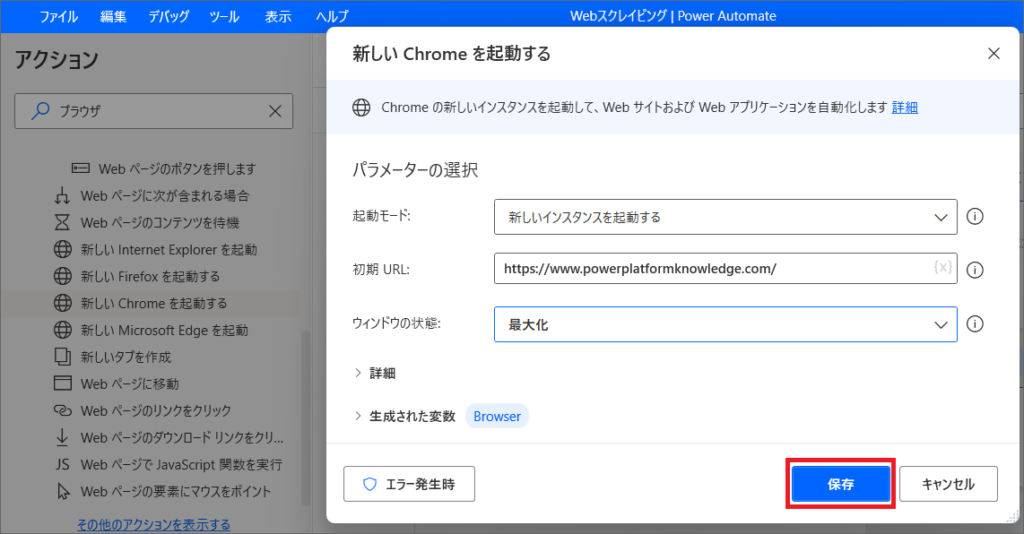
1.データを取得するウェブサイトを開く必要があるため、アクションでブラウザと検索し、リージョン1の中に「新しいChromeを起動する」アクションを追加します。
米ブラウザはEdge等、他のものでも大丈夫です。
2.初期URLを設定し、ウィンドウの状態は最大化しておきます。
※スクレイピングが禁止されていないWebサイトで試しましょう
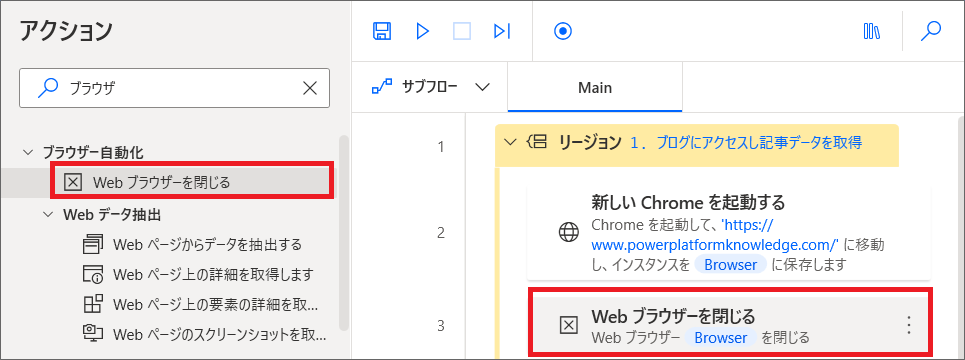
3.「ブラウザを起動する」アクションを追加したら、最後に必ず「Webブラウザを閉じる」アクションも追加します。
4.Webブラウザのインスタンスは、先ほど追加したブラウザの起動のアクションで保存された同じインスタンス”Browser”を選択します。
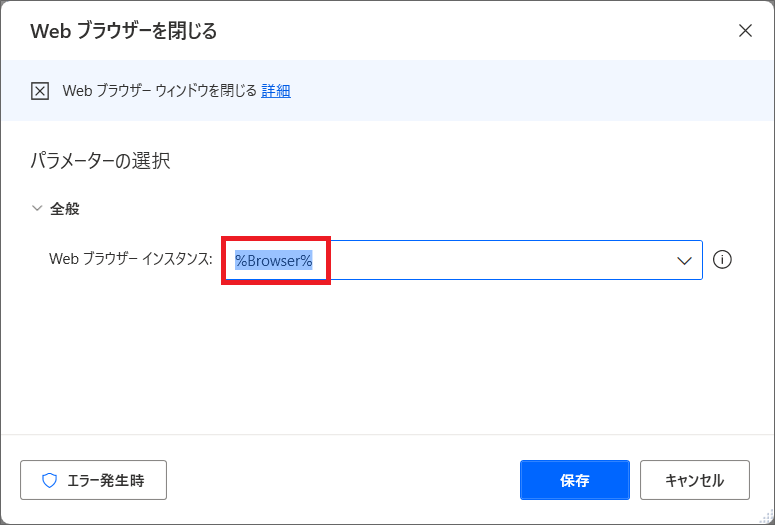
今回は一つしかブラウザを開かないので簡単ですが、複数ブラウザを開く処理を行っている場合は、インスタンスの選択に注意しましょう。
さて、ここまででブラウザが無事開けるかどうかテストします。
4.このままテストするとブラウザがすぐ閉じるため、「Webブラウザを閉じる」アクションの左(3行目)をクリックし、ブレイクポイントを置きます。
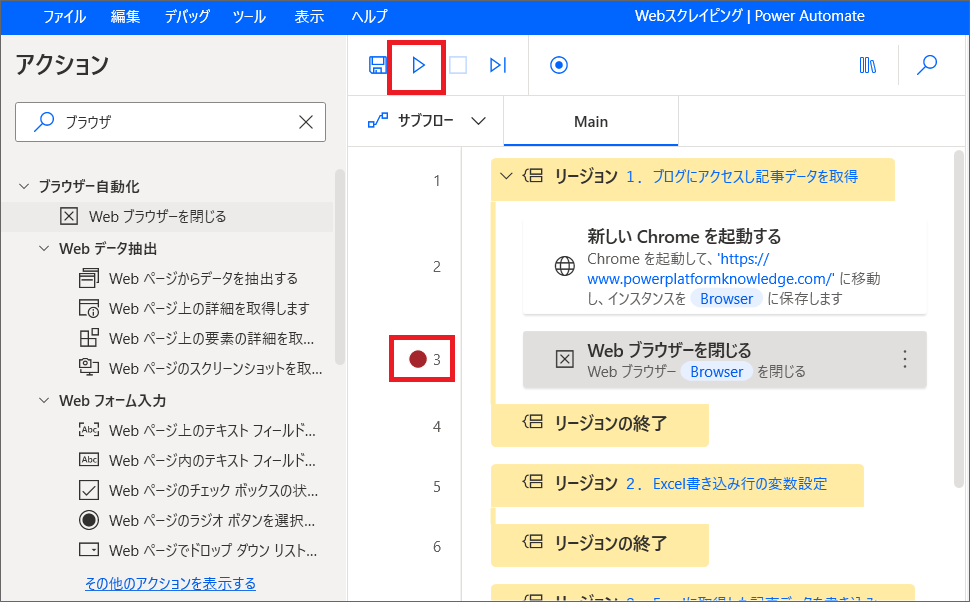
5.実行ボタンを押すとブラウザが起動し、指定したURLのサイトが表示されます。
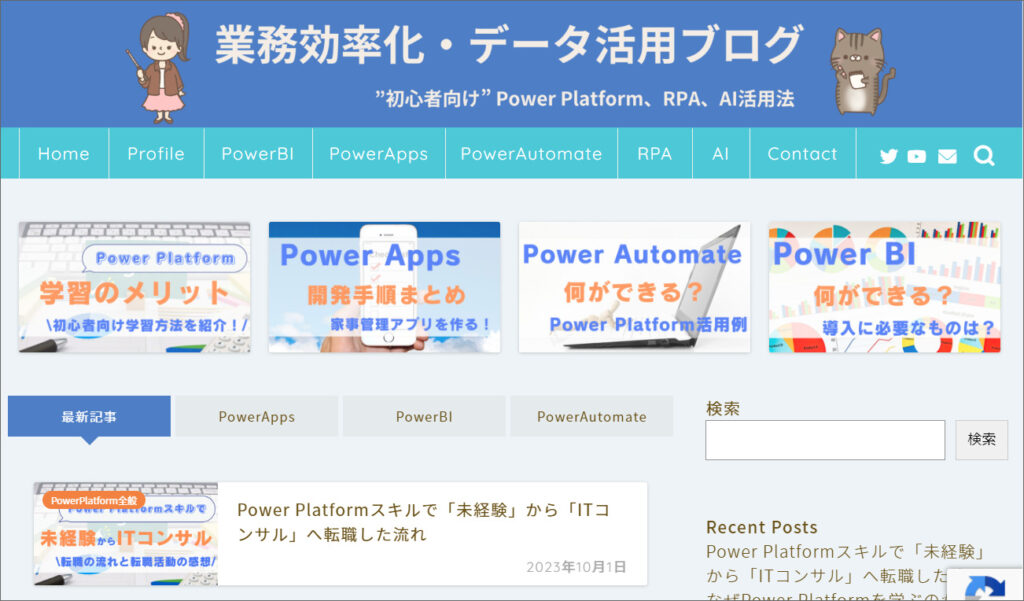
6.このブラウザを起動したままにして、次のアクションを設定するため、一旦停止をクリックします。
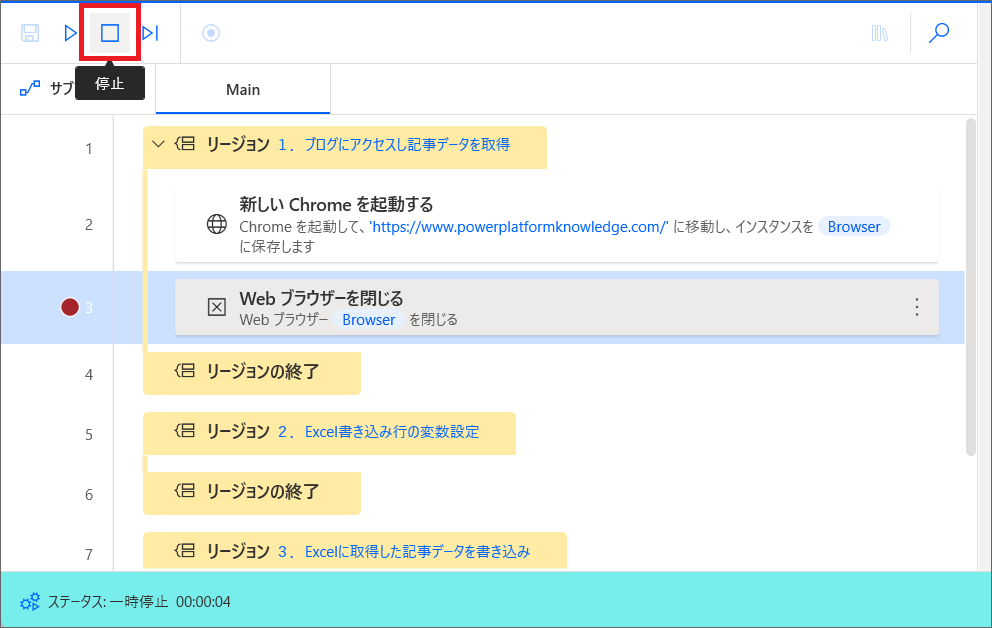
7.次はブログの記事情報を取得するため、「webページからデータを抽出する」アクションを、「Webブラウザを閉じる」アクションの上に追加します。
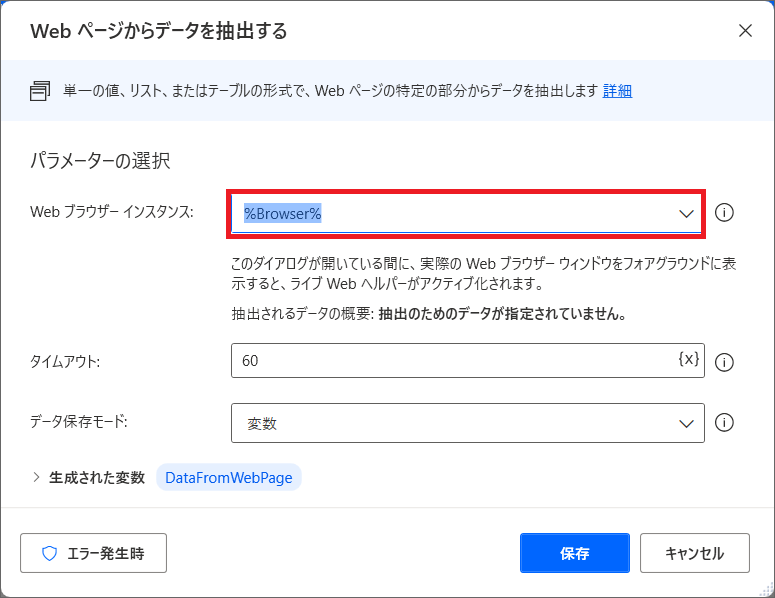
8.Webブラウザのインスタンスを選び、先ほど開いたブラウザに戻ると、抽出プレビューが表示され、抽出したい要素の上にカーソルを置くと、自動で赤枠が表示されます。
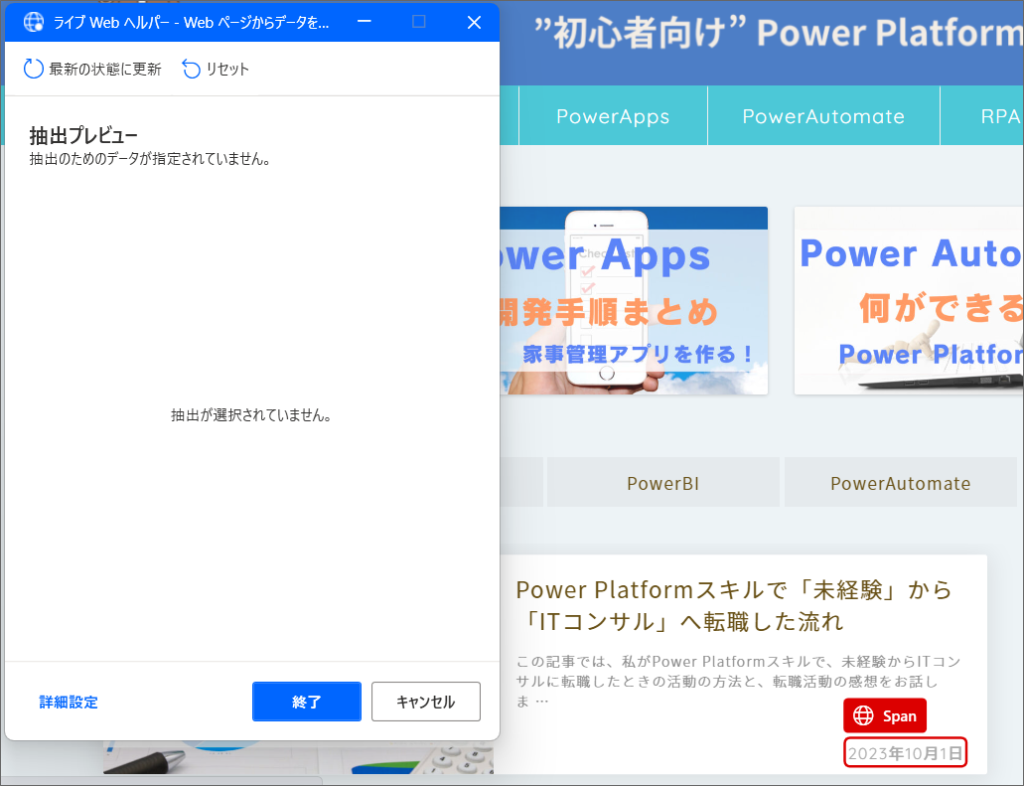
今回は試しに、ホーム画面の記事一覧の日付と、タイトル一覧を取得してみます。
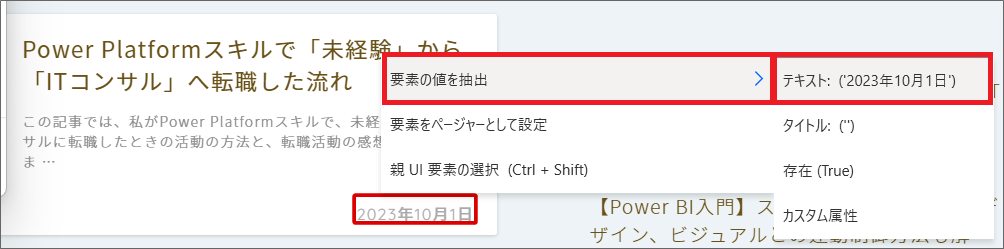
9.一番上の記事の日付にカーソルを当て、赤枠が表示されたら、右クリック>要素の値を抽出>テキストを選択します。
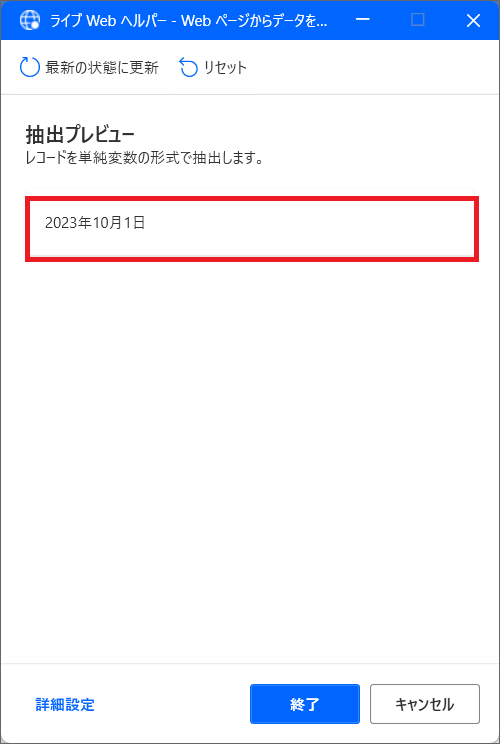
10.すると、抽出プレビューに日付が入ります。
11.同じようにタイトルも取得してみます。
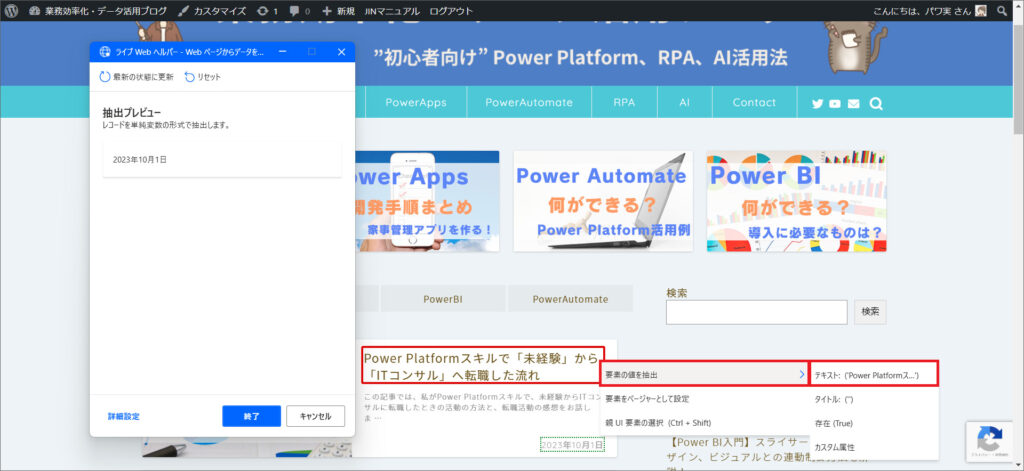
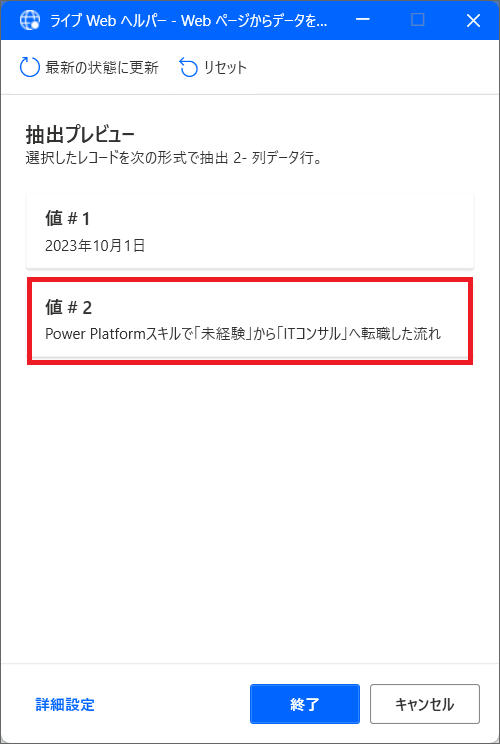
12.次に2つ目の記事に移り、また日付のテキストを抽出します。
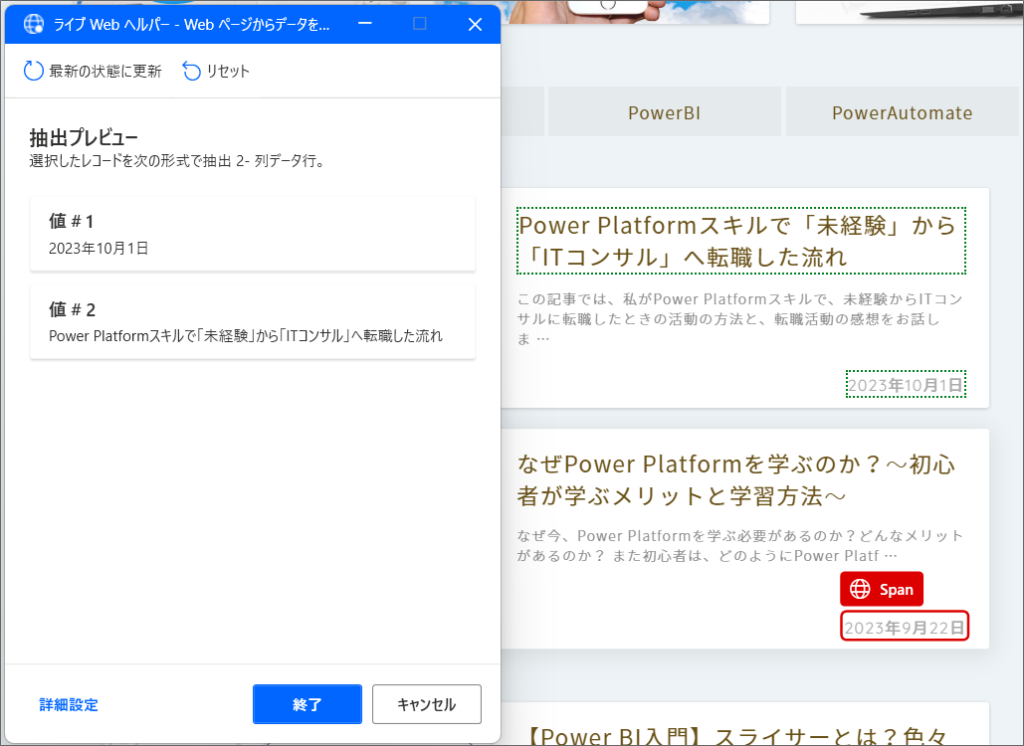
13.すると2つ目以降の記事の日付と、タイトルデータを自動で全て抽出してくれますので、終了をクリックします。
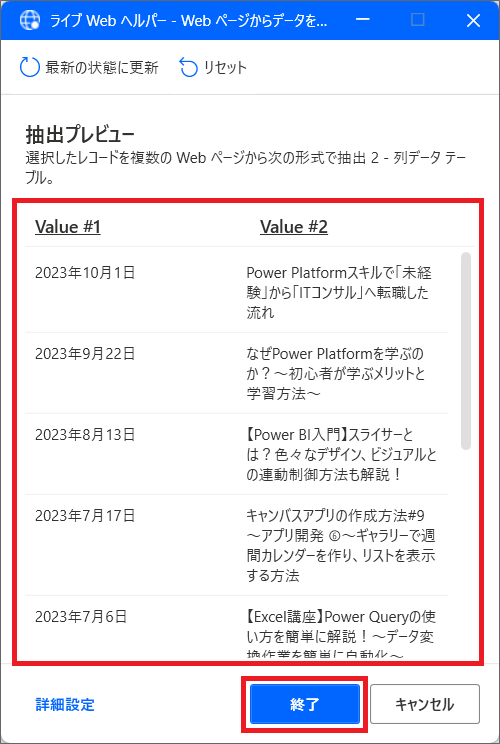
これはテーブル型の変数、DataFromWebPageとして、自動で保存されます。
14.PADの編集画面に戻り、「Webページからデータを抽出する」アクションで、保存をクリックしましょう。
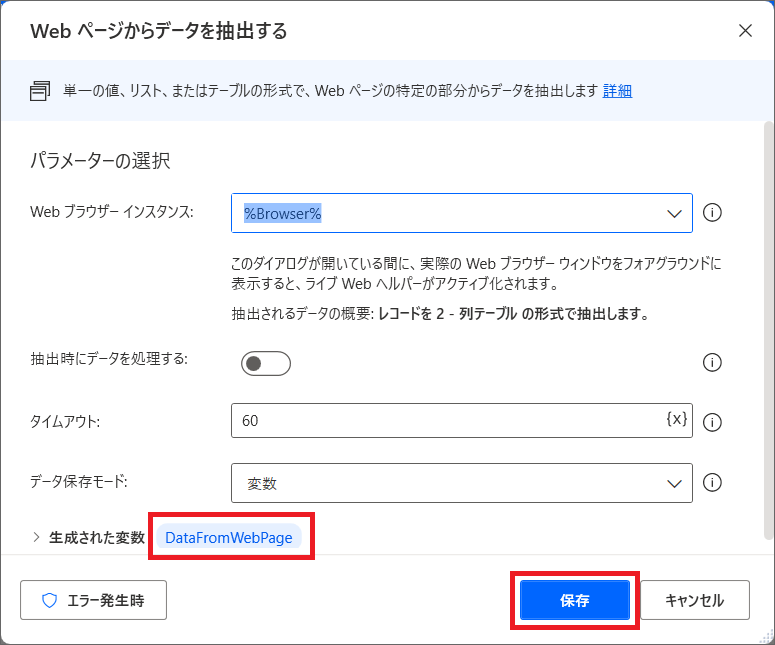
これでリージョン1は完了なので、試しに一旦ここまで実行してみましょう。
15.実行ボタンを押すとWebページが開き、情報を取得した後にブラウザを閉じます。
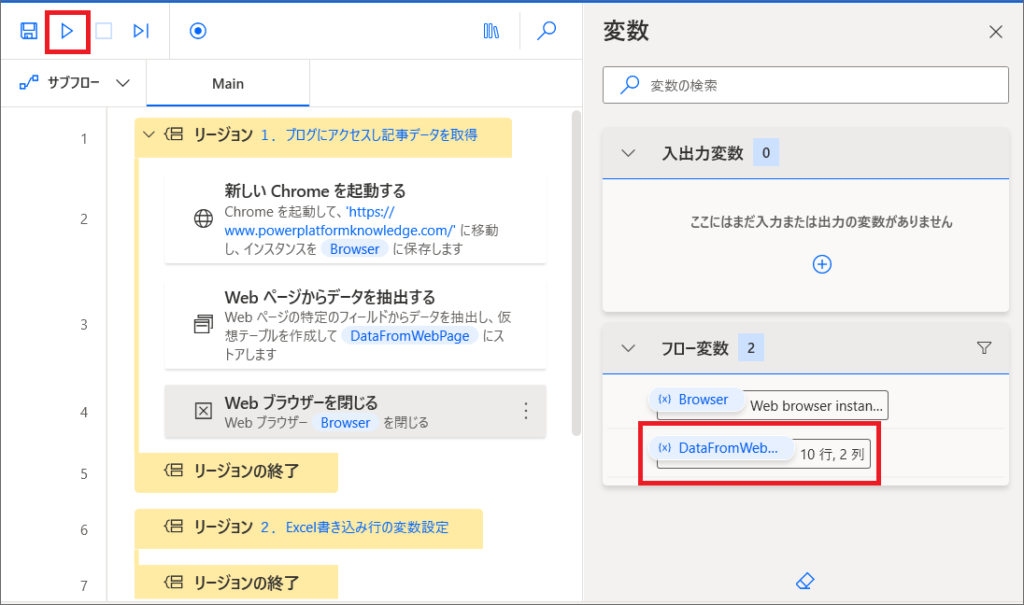
16.フロー実行後、右側の変数「DataFromWebPage」をダブルクリックすると、実際に取得した記事データが、テーブル型変数で保存されていることがわかります。

2.Excel書き込み行の変数設定
これは取得した記事データを1行ずつExcelに書き込むための行数を指定する変数です。
2行目から始めて、3行目、4行目とデータを書き込んでいきます。
1.アクションで変数を検索し、「変数の設定」をリージョン2の中にドラッグ&ドロップします。
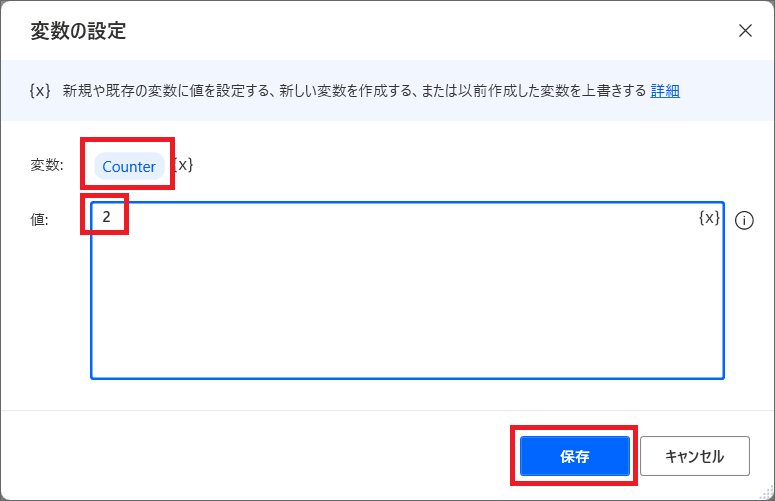
2.変数名を「Counter」とし、値に半角数字で「2」と入れて保存します。
リージョン2はこれで終わりです。
3.Excelに取得した記事データを書き込み
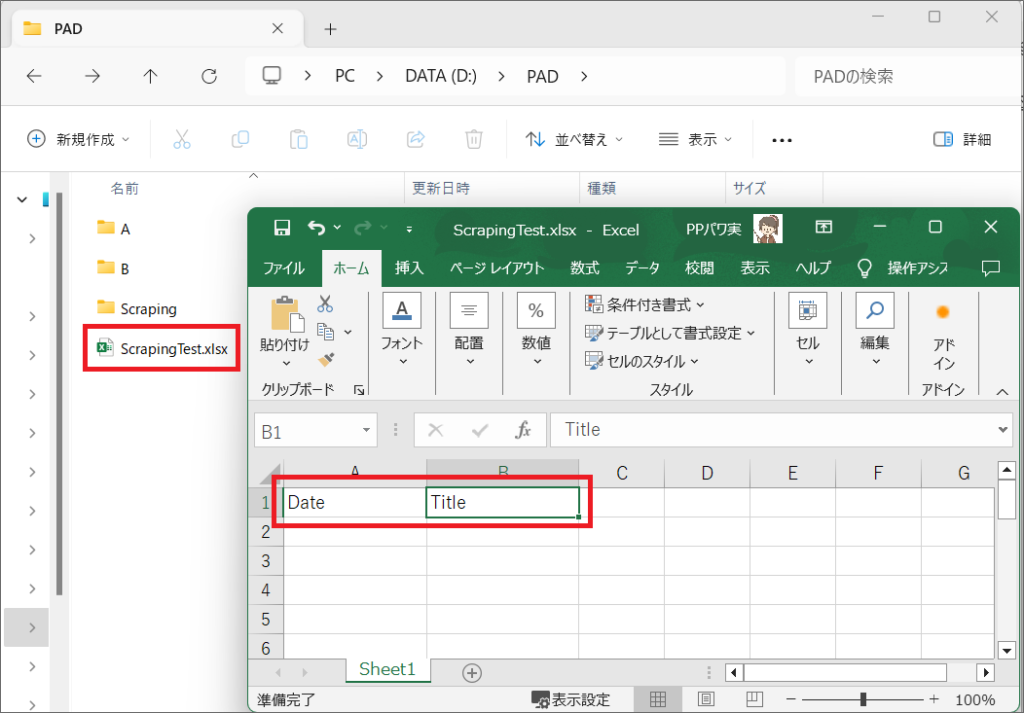
1.今回はあらかじめ、Excelをローカルフォルダに用意し、1行目にDate列と、Title列を用意しました。
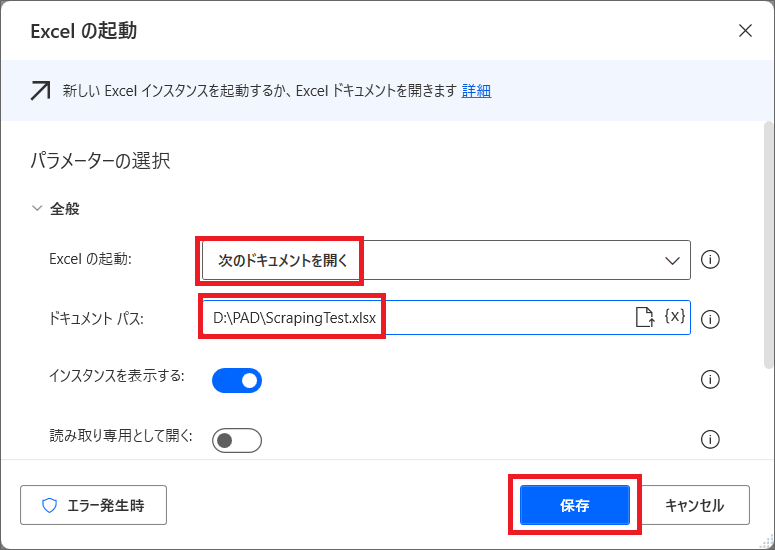
2.PAD編集画面で、「Excelの起動」アクションを検索し、リージョン3の中に入れて設定をします。
3.「次のドキュメントを開く」を選択し、Excelのファイルパスを設定して保存します。
※新規にExcelファイルを作成することもできます
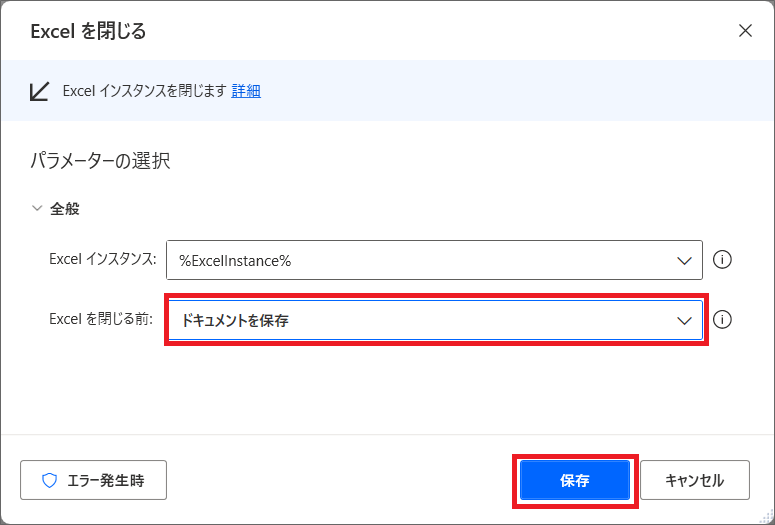
4.ブラウザと同様Excelも開いたら、最後に「Excelを閉じる」アクションをセットで追加します。
Excelを閉じる前は「ドキュメントを保存」を選択しましょう。
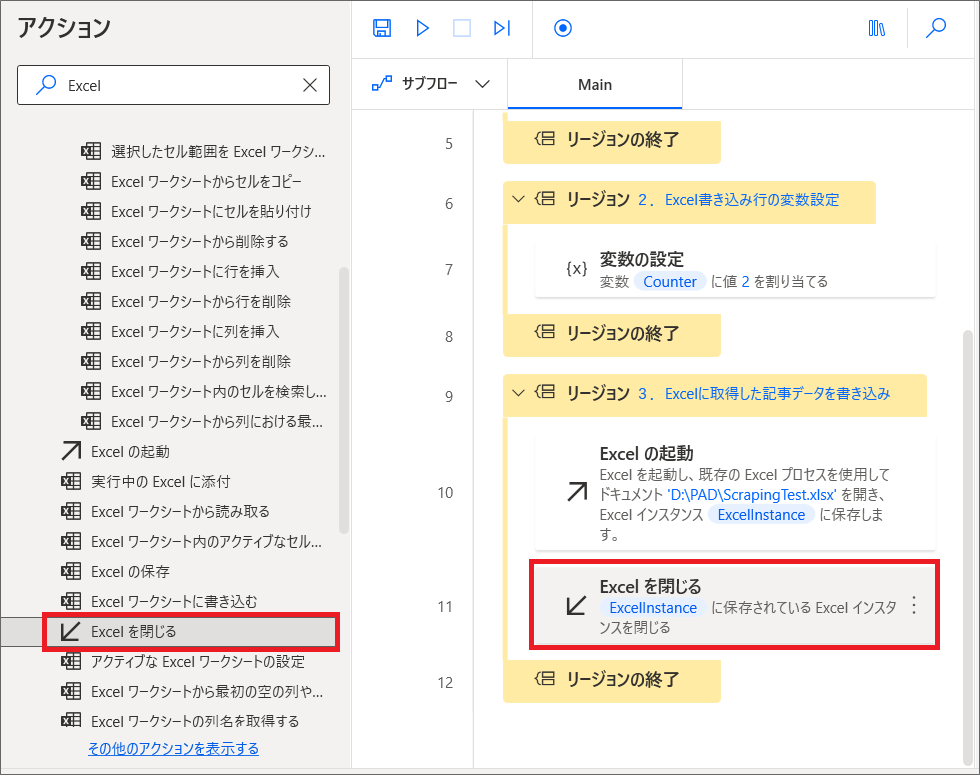
次に、先ほど取得したテーブル型変数「DataFromWebPage」のデータを、Excelに書き込みます。
この時テーブル型変数を1行ずつ取得して書き込む処理をするため、ループである「For Each」アクションを設定します。
5.「For Each」アクションをドラッグ&ドロップすると、「反復処理を行う値」の設定が必要になるため、{X}から「DataFromWebPage」を選択し、保存します。
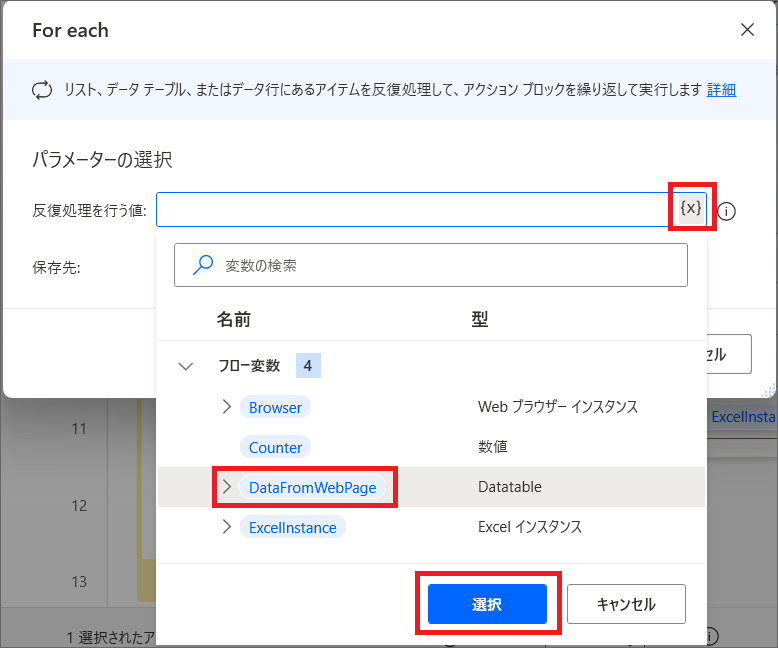
{X}をクリックすると、これまで作成された変数を選択することができます。
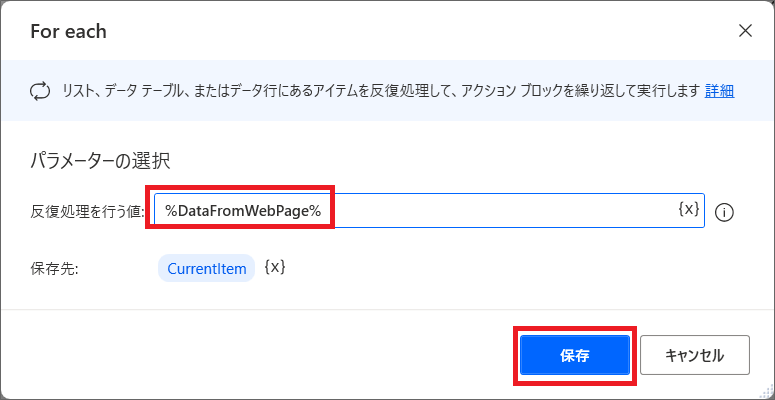
6.次に「For Each」の中に、「Excelワークシートに書き込む」アクションを追加します。
Excelのインスタンスを選択し、「書き込む値」はまず、変数「CurrentItem」を選択します。
※CurrentItemというのはDataFromWebPageの1行分のデータです。
7.このうち「日付列」データを取得したい場合、「%CurrentItem[‘Value #1’]」と書きます。
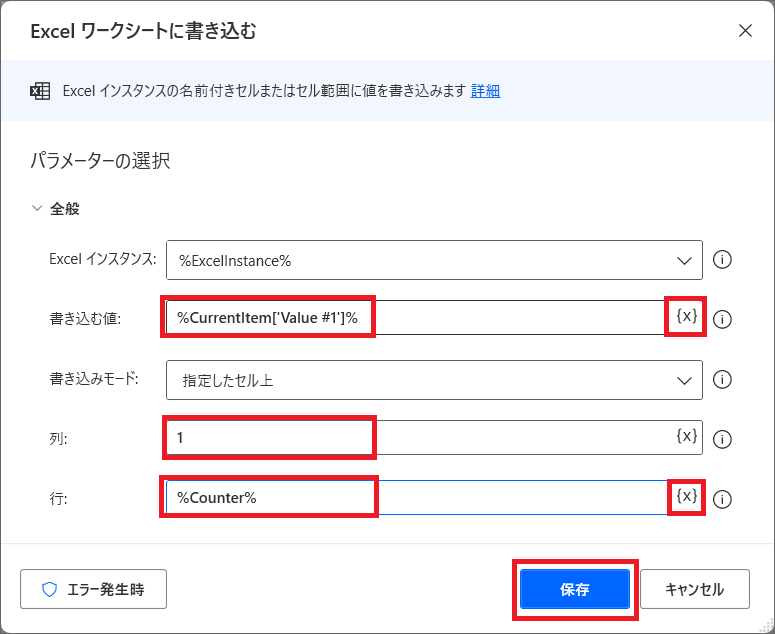
[Value #1]というのは、取得したデータの日付を持っている列を指します。
テーブルデータの中で、列を指定して値を取得したい場合、このような書き方で取得できます。
8.データを書き込む場所を、列と行で指定する必要があります。
日付データは1列目なので、列は「1」と入力します。
行ははじめ、リージョン2で設定した変数「Counter」(2行目)に書き込むため、変数の設定から「Counter」を選択し、保存します。
9.もう一つ「Excelワークシートに書き込む」アクションを追加し、同様の方法で記事のタイトルデータも書き込みましょう。
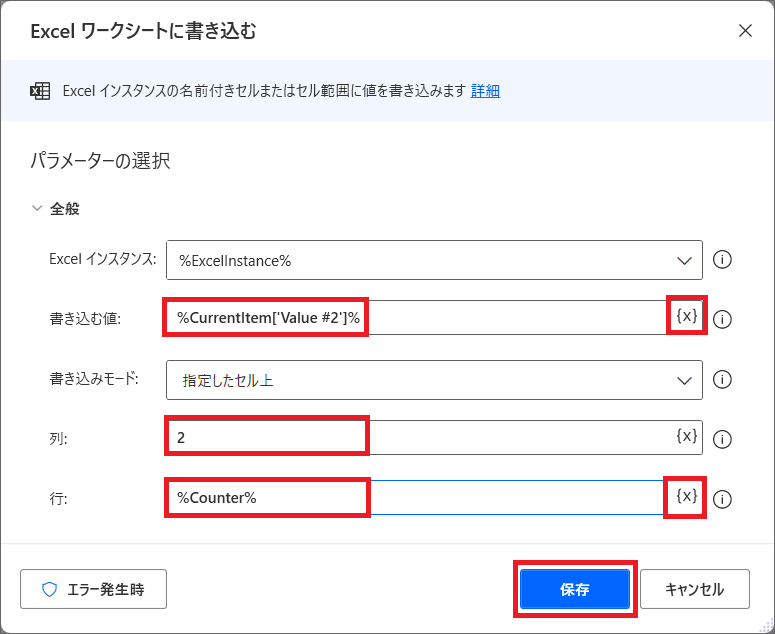
これでExcelへの書き込みもできました。
For Eachでは最初に、取得したテーブル型変数「DataFromWebPage」の1行目が、Excelの2行目に書き込まれ、次のループで「DataFromWebPage」の2行目が、Excelの3行目に書き込まれるようにします。
そのため「For Each」のループの最後に、変数「Counter」(Excelに書き込む行番号)を+1する必要があります。
10.「For Each」の中の最後に、「変数を大きくする」アクションを追加したら、変数「Counter」を選択し、大きくする値には「1」を入れましょう。
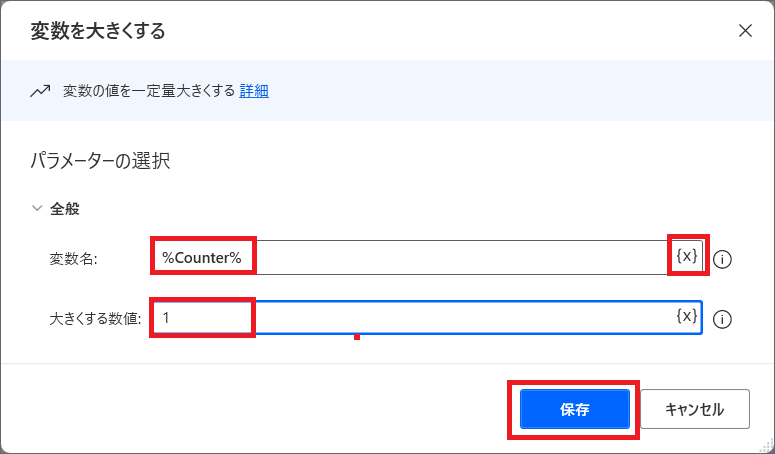
これで1回目のループの最後に、変数「Counter」(2)が、+1されて3になり、2回目のループでは、3行目にデータが書き込まれます。
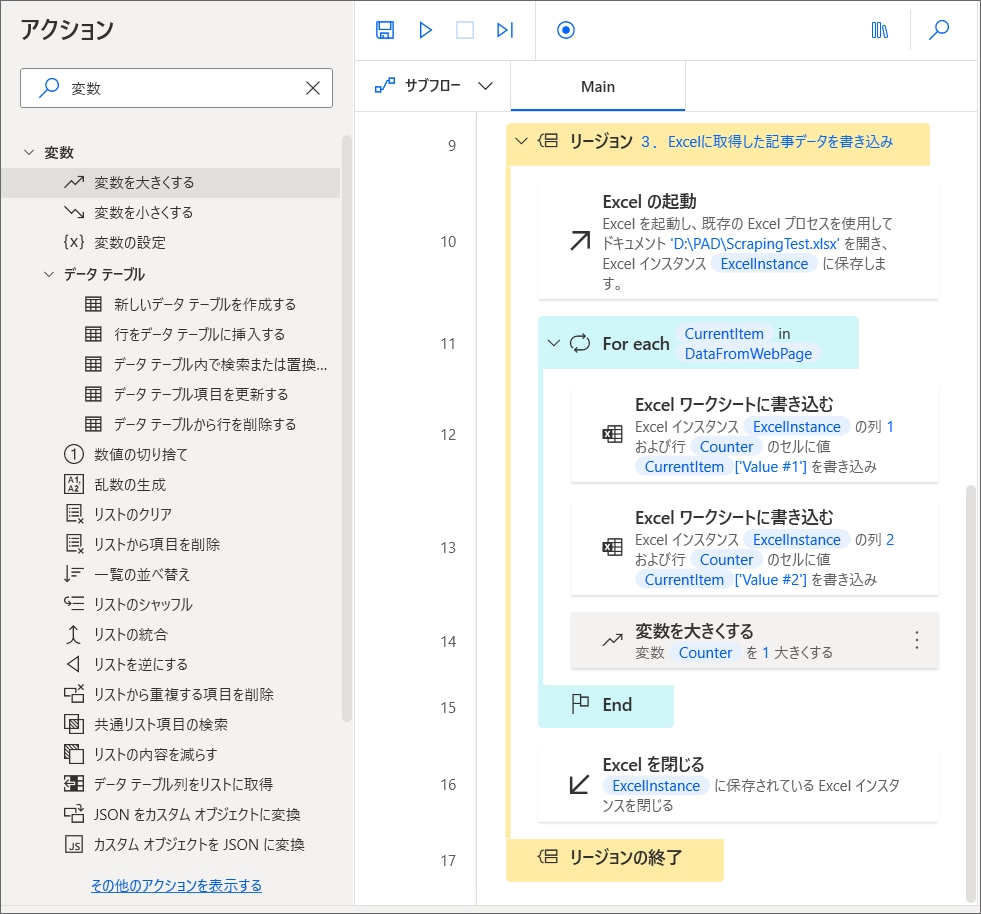
フローを実行して、ちゃんと記事情報が取得できるか確認します。
11.フローの実行が完了したらExcelを開き、ちゃんと記事情報が取得されていればOKです。
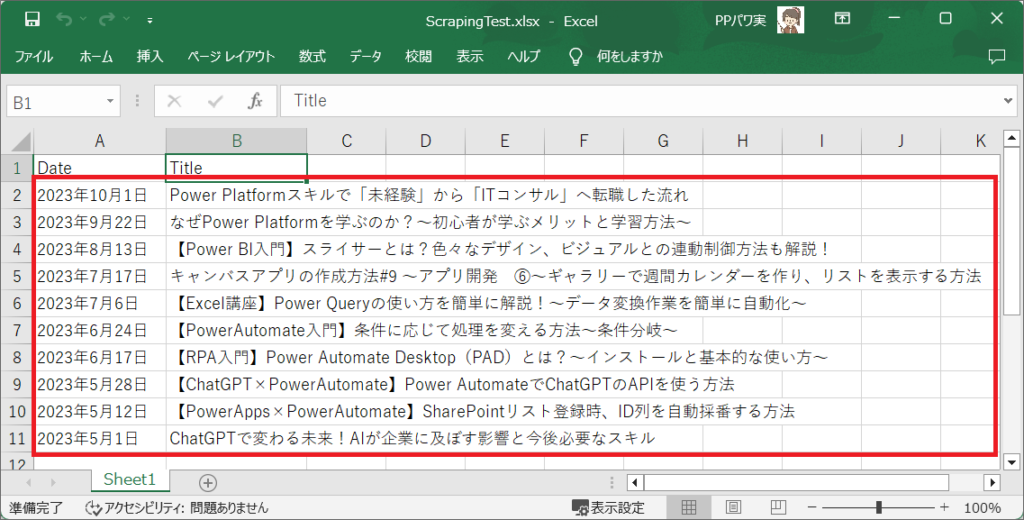
このような感じで、Power Automate Desktopを使ったwebサイトの情報を取得(スクレイピング)ができました。
最後に
この記事では、Power Automate Desktopについて、基本的な仕組みや基礎知識を解説し、記事情報をスクレイピングする簡単なフローを作成する方法を紹介しました。
自動化したい作業が、Power Automateと、PowerAutomate Desktop、どちらでも実現可能な場合は、Power Automateを使いましょう。
Power Automate Desktopでフローを実装する際、初めに作業の大まかな流れを整理して、リージョンを分けると便利です。








