
Power BIでテーブルの分け方や、リレーションシップをどうやって考えたらよいのか分かりませんぞ!

今回はPower BIのデータモデル設計の基本的な考え方を解説するよ!
この記事では、Power BIのデータモデルの考え方について、スタースキーマの概念と合わせて解説します。
- Power BIのデータモデルをどうやって考えていけばよいか
- スタースキーマの概念
- どのようにテーブルを分ければよいか
Power BIのリレーションシップとは何か?については、以下の記事も参考にしてください。

YouTube動画で見たいかたは、こちらからどうぞ!
Power BIのデータモデルとは?
Power BIを使ってデータを可視化するには、まずデータモデルを考える必要があります。
データモデル設計は、Power BIを使ったデータ分析で最も重要な部分ですが、Power BIを使い始めた人にはとても難しいと思います。
そもそもデータモデルの設計とは、以下のような、各テーブルと必要な列(データ)、テーブル間のリレーションシップを考えることです。
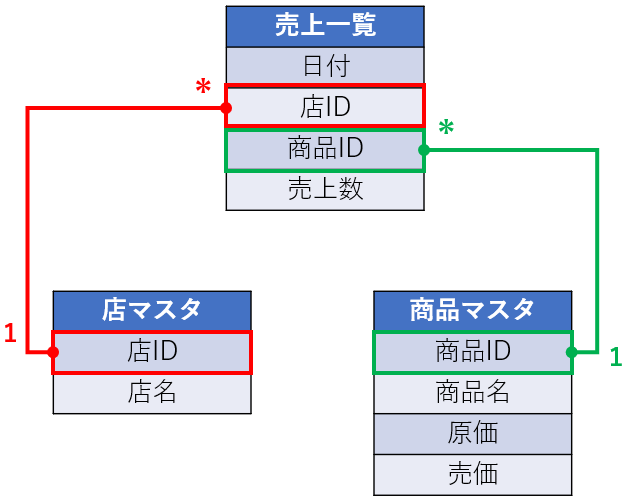
- テーブルの分け方や、各テーブルに何の列(データ)を入れるか
- 各テーブル間のリレーションシップ
ミムチはいつも全く分かりませんぞ…!
この後、データモデル設計の考え方を一つずつ解説していくね!
データモデルを考える際のポイント
Power BIのデータモデルを考える基本的な手順は、以下のようになります。
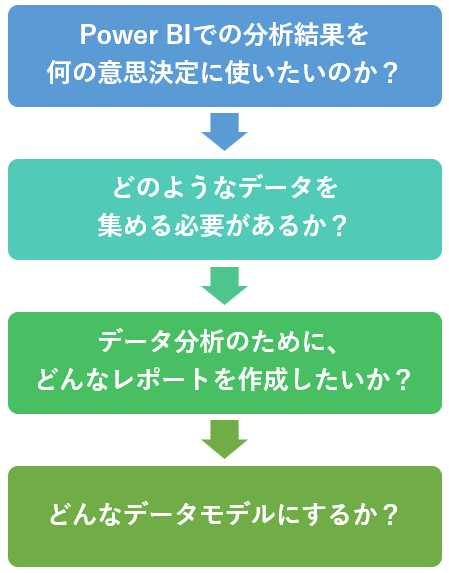
これを踏まえ、Power BIのデータモデルを考える際のポイントがいくつかあります。
- どのようなレポートにしたいか考える
- 一対多のリレーションシップを基本とする
- 不要なデータは削除する
- データモデルのメンテナンス性を考える
4つのポイントについて、一つずつ説明していきます!
どのようなレポートにしたいか考える
まずPower BIでどのようなレポートを作り、データ分析をしたいかは、事前に考えておくとよいでしょう。
Power BIでどのようなレポートを作成したいかによって、データモデルの設計が変わります。
その際は、そもそも何の意思決定に役立てるために、何のデータを使い、どんな分析をしたいかを整理しておきましょう。

一対多のリレーションシップを基本とする
Power BIでテーブル間のリレーションシップを作成する場合、基本的には一対多のリレーションシップとなるデータモデルとしましょう。
以前、Power BIで多対多のリレーションシップを作成する方法も解説しましたが、特性を分かっていないと意図しないレポート表示となる場合があるため、特に初心者の場合は避けた方がよいです。
多対多のリレーションシップの詳細は、以下の記事を参考にしてください。

不要なデータは削除・非表示にする
分析に使わない不要なテーブルや列は、Power Queryエディタの操作で、なるべく削除しておきましょう。
またPower BIに一旦取り込み、DAX等で列を追加した後も、データタブや、モデルタブで不要なテーブルや列を非表示にすることができます。
不要なテーブルや列を取り込まない方が、ファイルサイズを圧縮でき、パフォーマンスも向上します。
Power BIのユーザーには、データモデルを構築する人、レポートを作成する人、レポートを閲覧する人等がいます。
データモデルの構築者は、レポート作成ユーザーが分析に使わないテーブルや列は、レポート上で見せないようにすることが大事です。
データモデルのメンテナンス性を考える
Power BIで作成したデータモデルのメンテナンス性も非常に重要です。
あまりにテーブル数が多かったり、テーブル間のリレーションシップが複雑すぎると、作成者以外がメンテナンスできなくなってしまいます。
またユーザーがレポート作成しやすいように、あえてテーブルを分けすぎず、2つのテーブルをマージして1つにしたものを使う場合もあります。
スタースキーマを理解する
この「スタースキーマ」とは何ですかな?
ファクトテーブルとは、レポートで値として表示するテーブルで、ディメンションテーブルは、凡例や軸等、値に対する切り口として表示するテーブルです。
Power BIでは「スタースキーマ」を基本としたデータモデルを設計するのが最適と言われています。
スタースキーマとは?
スタースキーマとは、例えば以下のようなモデルのことです。
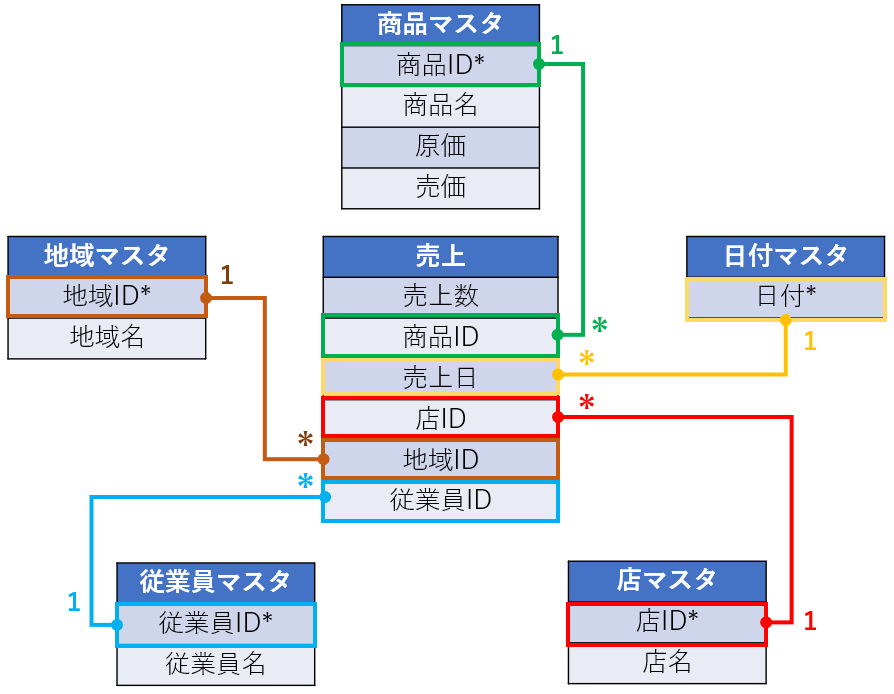
中央に売上テーブル(ファクトテーブル)があり、周りには商品マスタ、日付マスタ、店マスタ等、複数のディメンションテーブルがあります。
そして売上テーブル(ファクトテーブル)と、その他のテーブル(ディメンションテーブル)が多対一でリレーションシップされている状態です。
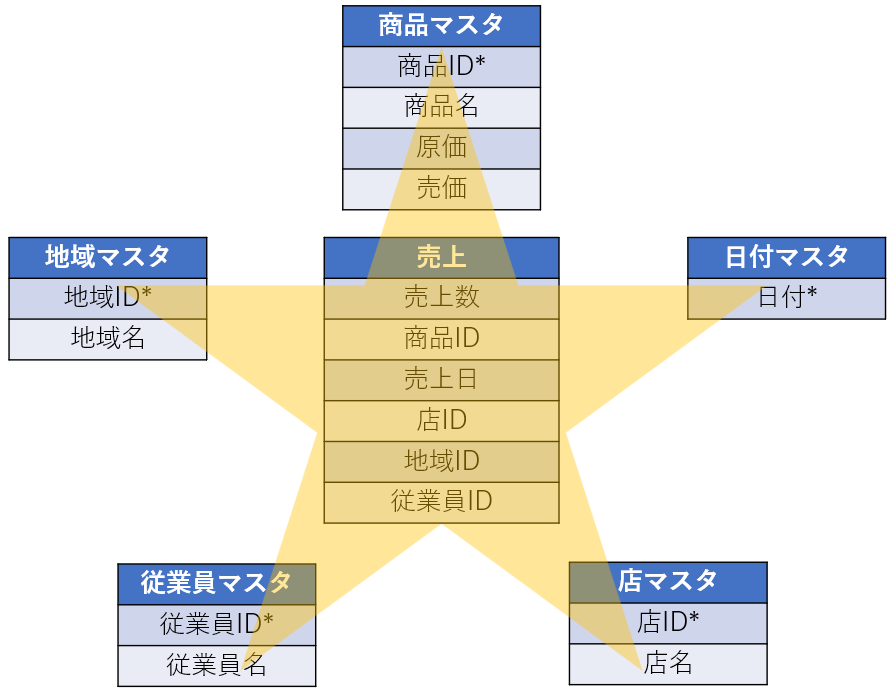
このデータモデルが、星のような形になっていることから、「スタースキーマ」といいます。
※ファクトテーブルが複数あったり、ディメンションテーブルが5つでない場合もあります
この「スタースキーマ」が、Power BIで最適なデータモデルとされているため、これを理解することがとても重要です。
ファクト(値)と、ディメンション(切り口)の役割
ファクトテーブルと、ディメンションテーブルは、以下のように分けて考えます。
<ファクトテーブル>
- 販売額、注文数、気温等の「値データ」を持つテーブル
- レポートで「値」に入れる列を持つ
<ディメンションテーブル>
- 商品、場所、日付等、値に対する「切り口データ」を持つテーブル
- レポートで「凡例」や「軸」に入れる列を持つ
上述したように、Power BIではファクトテーブルに対して、ディメンションテーブルが、多対一でリレーションシップしているのが「スタースキーマ」です。
ファクトテーブルには、売上額、注文数等の数値データの他、商品IDや、店ID等、ディメンションテーブルとリレーションシップするためのキー列を持ちます。
ディメンションテーブルは、例えば商品マスタテーブル等があり、商品ID、商品名、その他商品情報のデータ列を持ちます。
データの正規化を行う
しかしファクトテーブルと、ディメンションテーブルをどう分ければよいのかは中々難しいですな…
正規化されたデータと、非正規化されたデータの違いは、以下のような感じです。
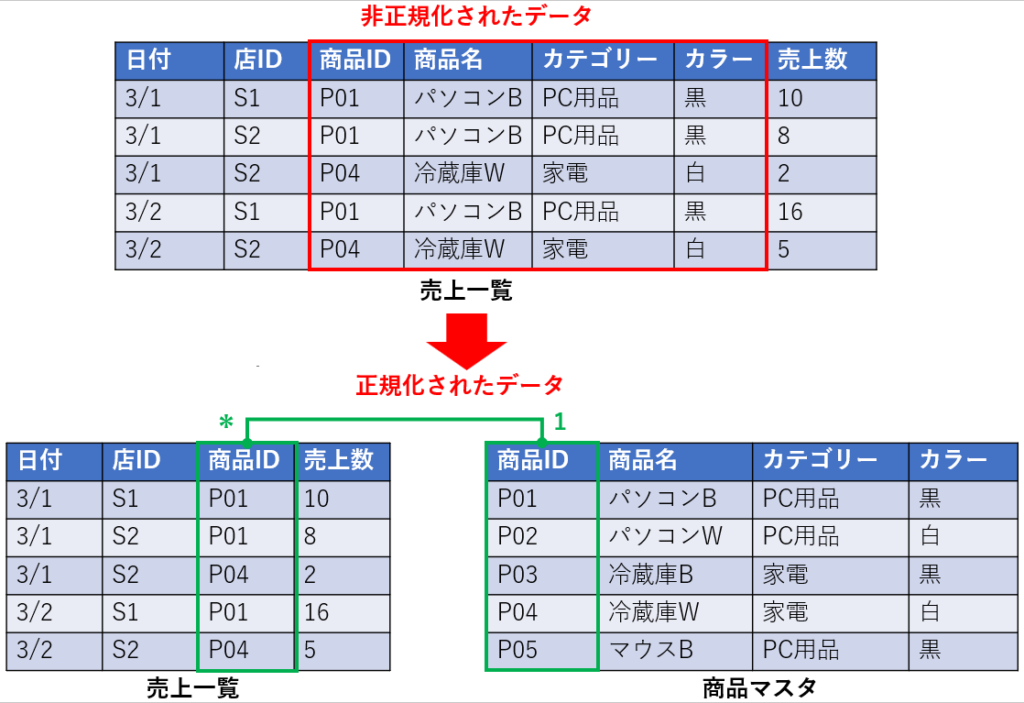
上のように、商品ID(キー列)以外に、商品名、カテゴリー、カラー等、商品関連データを持つ場合は、非正規化されているデータになります。
非正規化されているデータは、同じデータ(重複データ)が繰り返し格納されるため、PowerQueryを使って、下のような正規化されたテーブルにすることが望ましいです。
正規化されたテーブルでは、売上一覧と、商品マスタにテーブルを分け、売上一覧テーブルには、商品関連の列は、商品ID列のみ持つ形になります。
商品名、カテゴリー、カラー等の商品関連データは、商品マスタテーブルに格納し、商品ID列で一対多のリレーションシップを作成するというわけです。
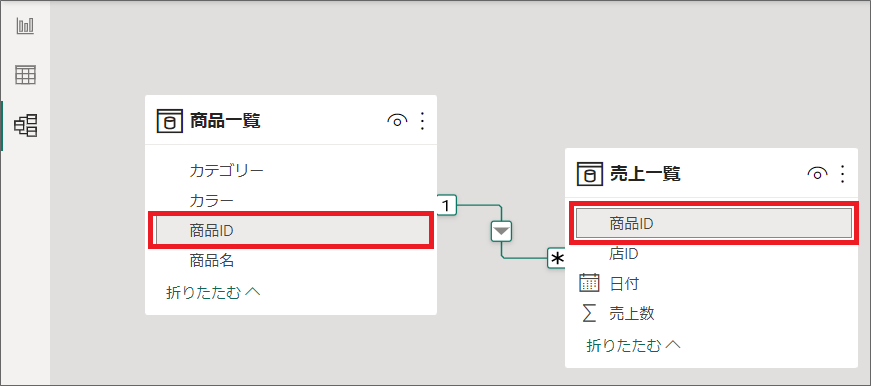
実際のPower BI画面では、モデルタブで、以下のようにリレーションシップをします。
レポートタブでは、例えば以下のように、値(ファクト)には売上数の合計、凡例や詳細(ディメンション)にはカテゴリーや、店データ等を入れます。
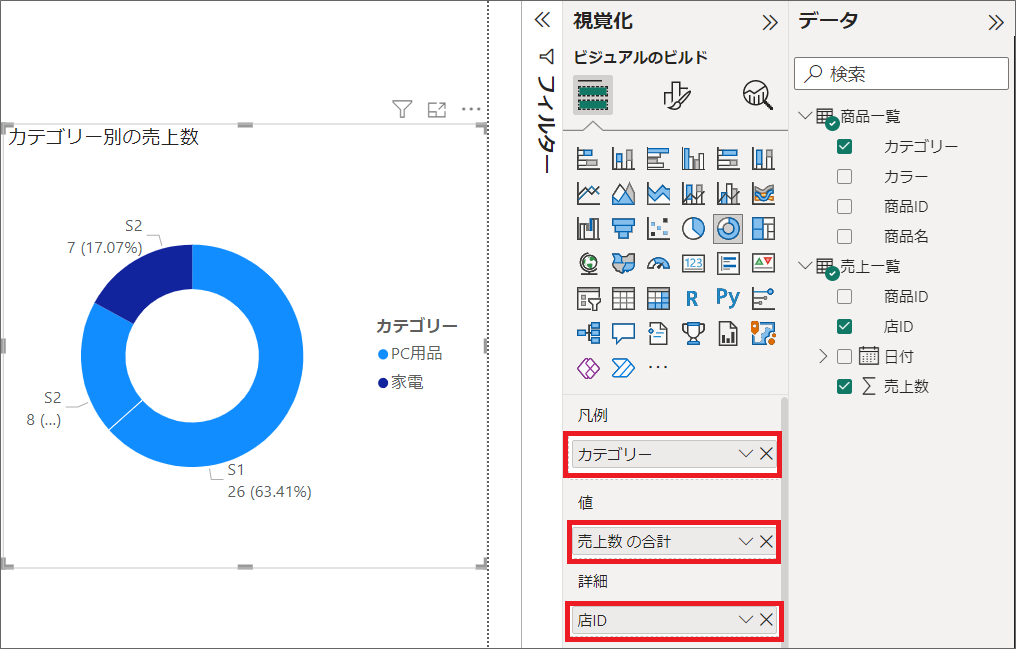
※店マスタもディメンションテーブルとして作成し、リレーションシップを作成するとよいです
非正規化データを、正規化することでテーブルを分けて、スタースキーマの考え方でリレーションシップを作成していけばよいのですな!
システムから出力される元データは、非正規化されているデータも多いから、それをPowerQueryのデータ変換で、正規化していく必要があるよ。
まとめ
この記事では、Power BIのデータモデルの考え方について、スタースキーマの概念と合わせて解説しました。
スタースキーマとは、ファクトテーブル(値データ)に対して、ディメンションテーブル(切り口データ)が、多対一のリレーションシップを作成するデータモデルの考え方です。
Power BIでは、元データが非正規化されたデータの場合は、Power Queryによって正規化されたデータに変換し、スタースキーマの考え方でデータモデルを作成していきます。
是非、この記事を参考にしてPower BIのデータモデルを考えてみてください。







