


この記事では「Microsoft Fabric」とは何かを簡単にお話し、Fabricを実際に使ってOneDriveのデータから、Power BIレポートを作成してみる方法を紹介します。
- Microsoft Fabricの概要
- Microsoft Fabricで使えるデータストアの比較
- Microsoft FabricでPower BIレポートを作成してみる方法
Youtube動画で見たい方は、こちらからどうぞ!
Microsoft Fabricとは?
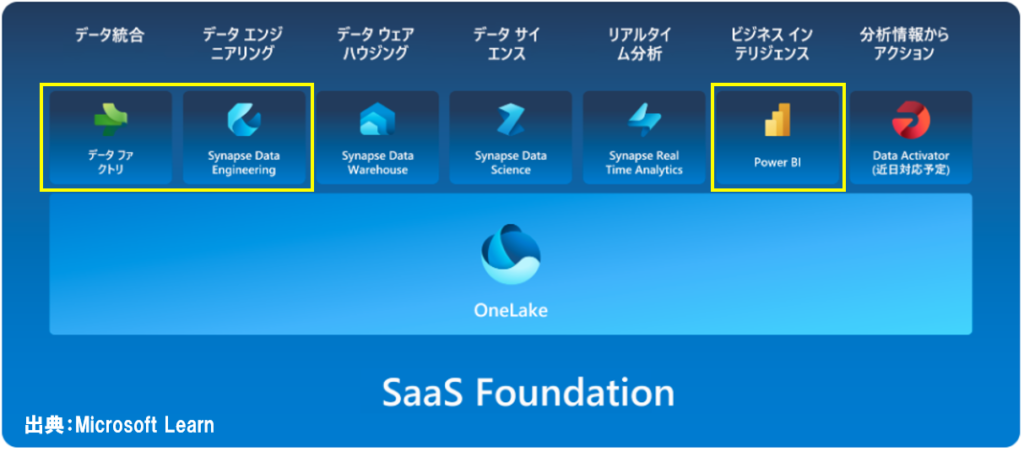
Microsoft Fabricの概要
Microsoft Fabricはあらゆるデータを統合し、ビッグデータ分析や、機械学習、リアルタイムデータ監視等ができるSaaSサービスです。
あらゆるデータは「OneDrive」のデータ版である「OneLake」で統合できます。
OneLakeでは、AmazonやGoogle等他社のサービスに格納したデータへも、ショートカット機能を利用することで、データの複製や移動をすることなく、1か所にまとめて分析することができます。
Power BIと何が違うのか?
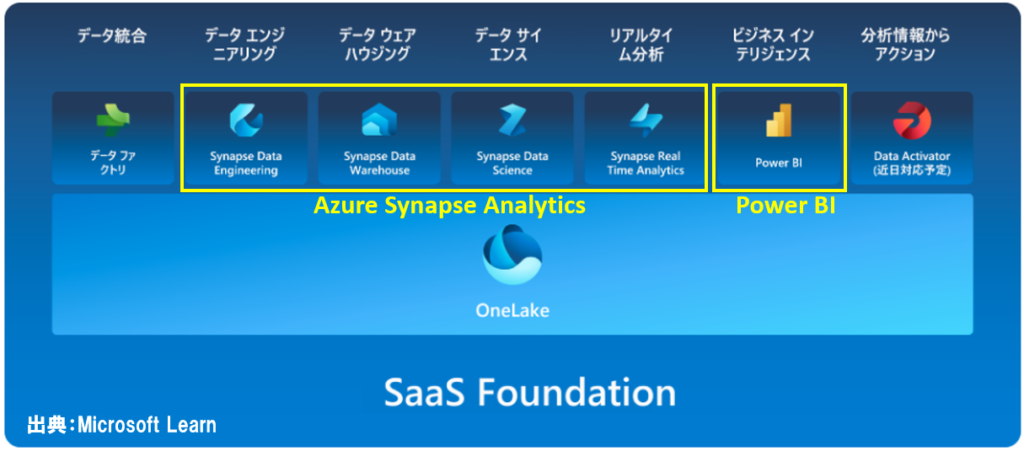
Microsoft Fabricの機能のざっくりとしたイメージとしては「Power BIサービスに、Azure Synapse Analyticsの機能が統合されたもの」と考えると分かりやすいです。
これまでPower BIを使ったビッグデータ分析をする場合、一つの選択として「Azure Synapse Analytics(PaaSサービス)」と、「Power BI(SaaS)」の連携がありました。
Azure Synapse Analyticsを使うと、大規模なデータのETL処理(データの取得、データ変換、ストレージに格納する処理)ができます。
そして加工済みデータを格納したAzure上のデータストアにPower BIから接続し、レポート作成や分析等を行うことができました。
今回「Azure Synapse Analytic」の機能がPower BIサービスに統合され、Microsoft FabricというSaaSサービスでビッグデータ分析や機械学習などもできるようになりました。
エクスペリエンスの概要
続いて簡単に、Microsoft Fabricのコンポーネント(=エクスペリエンス)について説明します。
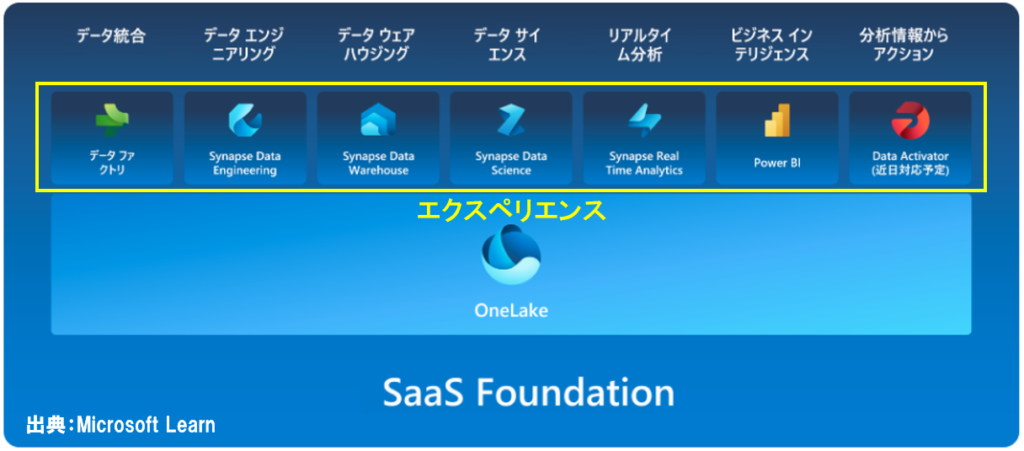
データファクトリ
「データファクトリ」は、データフローを作成し、大規模なデータの移動や、データ変換処理を実行できます。
データフローはほぼ、Power Queryと同様の操作で使えるので、Power BIユーザーは比較的馴染みやすいと思います。
またパイプラインを作成し、データのコピーや、データフローの更新、ループや条件などのロジックを作成することができます。
データエンジニアリング
「データエンジニアリング」では、「レイクハウス」というデータを格納できるデータストアを作成できます。
レイクハウスに格納したデータは、Apache Sparkという大規模データを処理するためのフレームワークを使い、Python、SQL、R言語等を利用し、データ変換やデータ分析、機械学習等に使うことができます。
またPower BIユーザーは、レイクハウスのデータから「セマンティックモデル(Power BIのデータモデル)」を作成し、レポート作成することができます。
データウェアハウジング
「Data Warehouse」は一言でいうと、大体SQL Serverの機能を提供しています。
CSV等の構造化データを格納でき、T-SQL(SQLのような言語)でクエリを実行することもできます。
どっちのデータストアを使えばよいのですかな?
データストアの選択
データストアの選択については、Microsoftの公式ページで紹介されています。
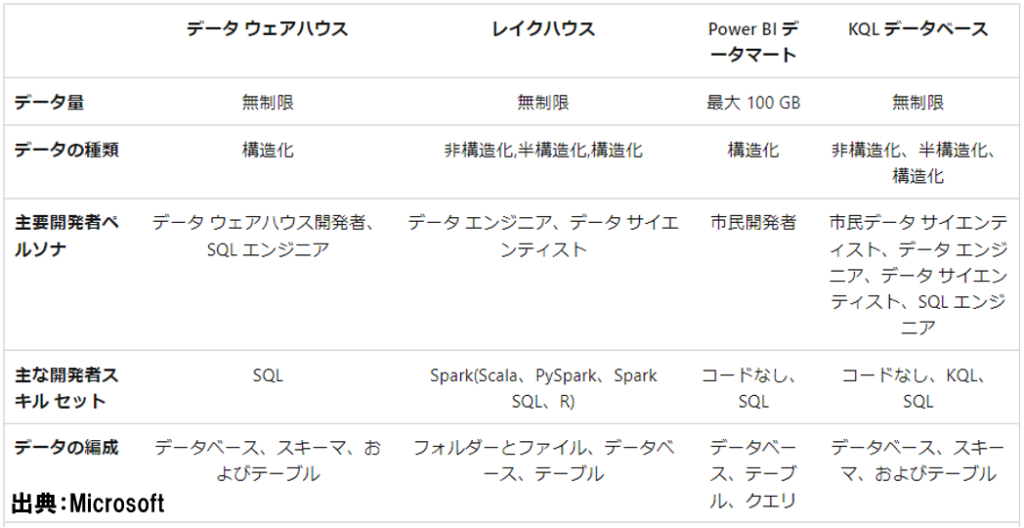
データ量
100GB以下のデータであれば「Power BIデータマート」、それ以上のデータであれば「データウェアハウス」、「レイクハウス」、「KQLデータベース」のいずれかを使います。
データの種類
CSVのような構造化データのみであれば「データウェアハウス」が使えますが、jsonのような半構造化データや、画像ファイルのような非構造化データを含む場合、「レイクハウス」か、「KQLデータベース」になります。
「KQLデータベース」はリアルタイム分析データの格納に適しているようです。
使用する言語
「データウェアハウス」はSQLでデータ操作ができますが、PythonやR言語を使い、機械学習もしたい場合等は「レイクハウス」を使います。
このように、データ量や、データの種類、利用用途、開発者の得意な言語等に合わせて、データストアを選択できます。

データサイエンス、リアルタイム分析、Data Activator
残りのエクスペリエンスは、ざっと以下のような機能を提供しているようです。
- データサイエンス:Sparkを利用して、PythonやR言語を使った機械学習ができる
- リアルタイム分析:IoT等のデータを利用したリアルタイム分析が可能
- Data Activator:リアルタイム分析データ等から、異常値を検知したときにアラートを通知する
Microsoft Fabricでレポート作成してみる!
今回試してみること
今回のデモでは「データファクトリ」、「データエンジニアリング」、「Power BI」を使ってみました!
データストアは「レイクハウス」を使います。
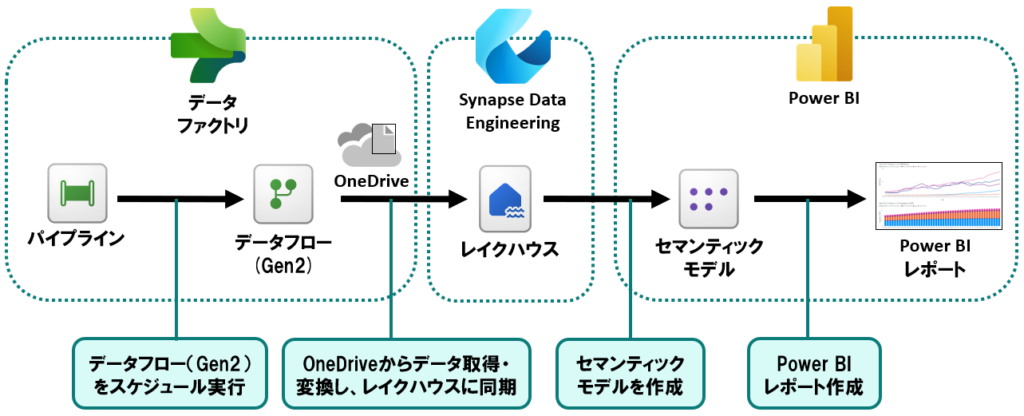
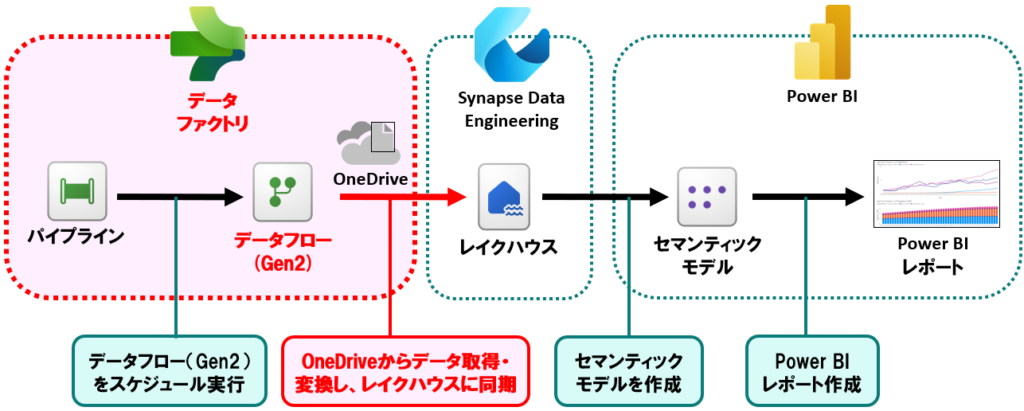
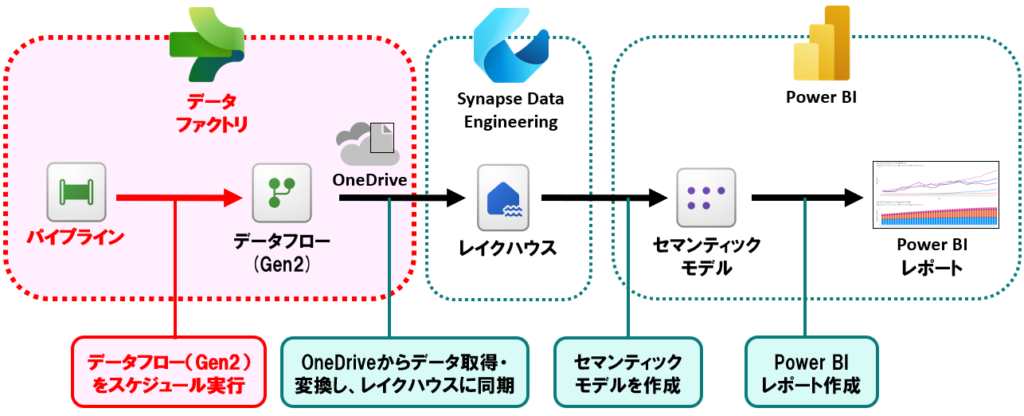
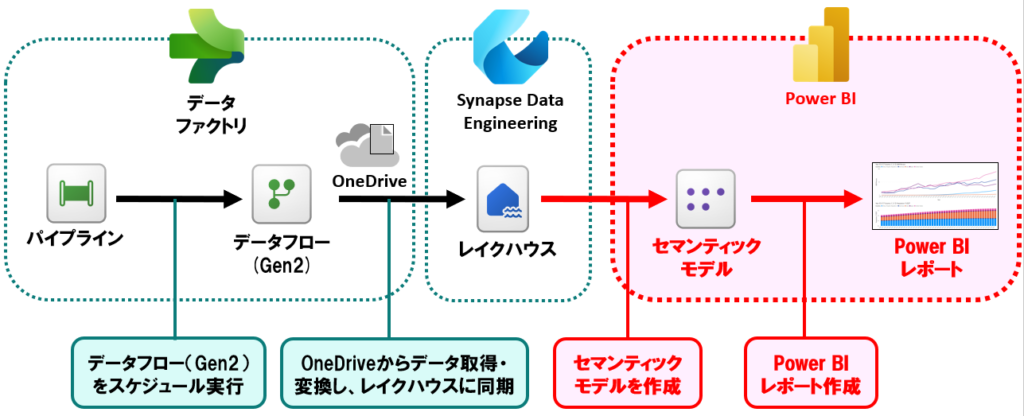
全体的な構成としては、以下のような感じです。
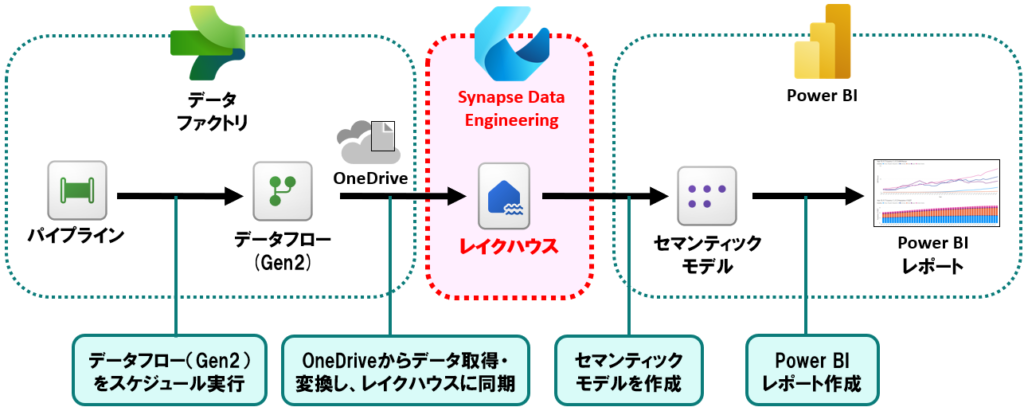
今回実現したこと
- パイプラインで、データフロー(Gen2)をスケジュール実行し、データフローが失敗したら通知をする
- データフロー(Gen2)は、OneDriveに格納した毎月の家計簿データ(CSV)を取得し、データ変換した後にレイクハウスに格納する
-
レイクハウスに格納したデータから、Power BIのセマンティックモデルを作成し、レポート化する
データエンジニアリング:レイクハウスを作る
最初に、データを格納する「レイクハウス」を作成します。
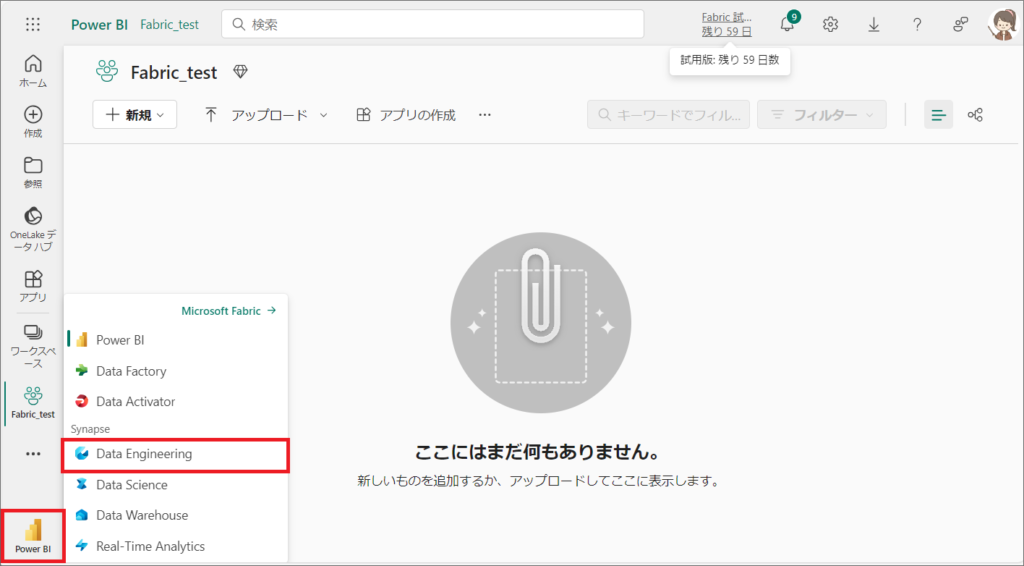
1.まずはFabricを開き、Fabric用のワークスペースを新規に作成します。
※Fabricのワークスペースには、Fabricコンテンツというマークが表示されます
Fabricは2023年12月現在、60日間の無料試用版が提供されています。
2.左下の「Power BI」アイコンをクリックすると、ここから利用するエクスペリエンスを選択できるので、「Data Engineering」を選択します。
3.「レイクハウス」をクリックし、任意の名前で作成します。
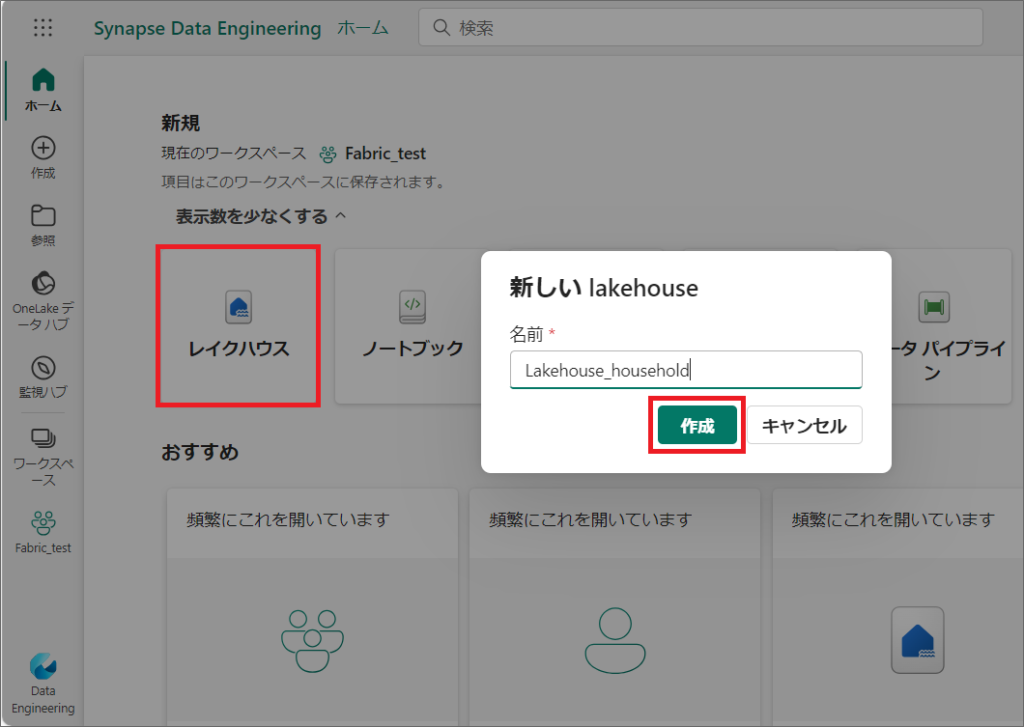
しばらくすると、レイクハウスが作成されます。
レイクハウスは「テーブル」と「Files」に分かれていて、色々なデータを格納することができます。
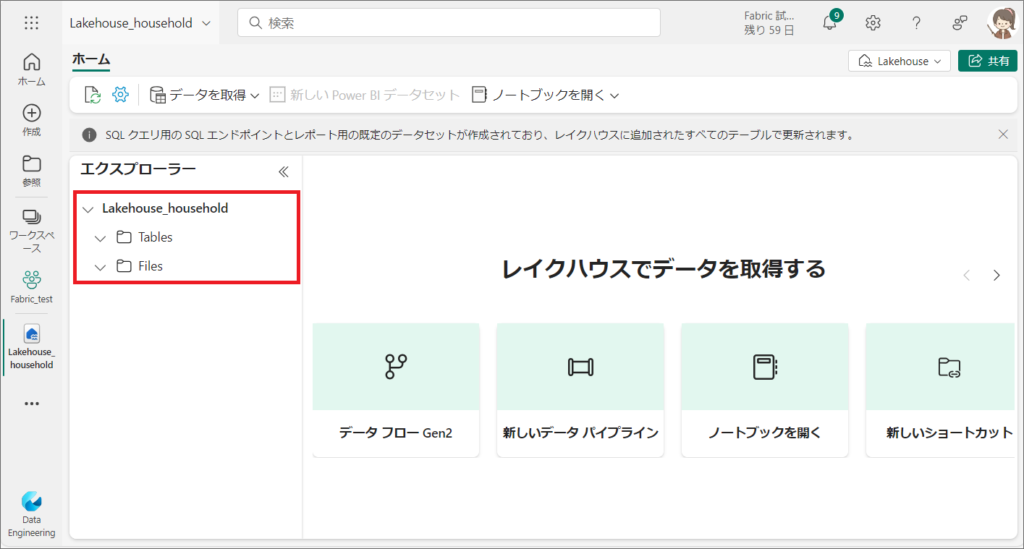
4.右上に「SQLエンドポイントが正常に作成されました!」と表示されたら準備完了です。
データファクトリー:データフロー(Gen2)を作成
次に、OneDriveからデータを取得し、データ変換後に、レイクハウスに格納するための「データフロー(Gen2)」を作成します。
1.先ほど作成したレイクハウスを開き「データを取得」から「データフローGen2」をクリックします。
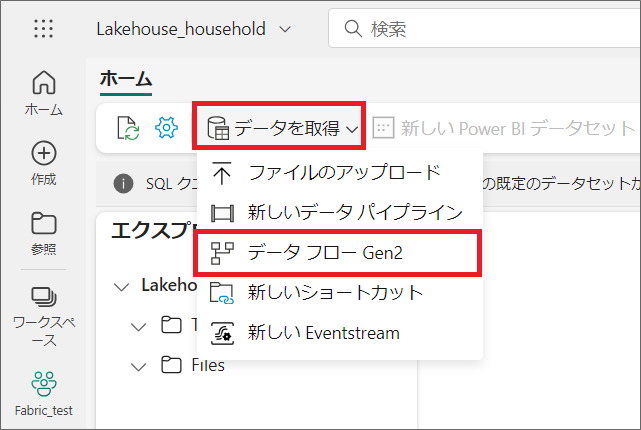
Power Queryの画面が開くので、これまで使っていたPower Queryと同様の操作で、データを取得、変換していきます。
今回は、ChatGPTで架空の家計簿データを作成し、CSVファイルで保存しました。
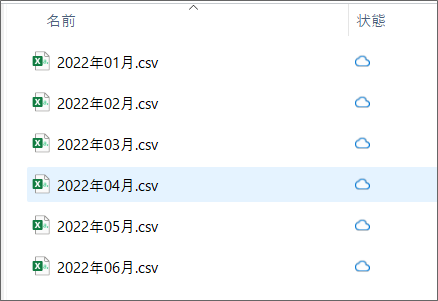
CSVファイルは毎月出力され、OneDriveに保存されているとします。
※中身はすべてダミーデータです

2.Power Queryで「データを取得」から、OneDriveからデータを取得します。
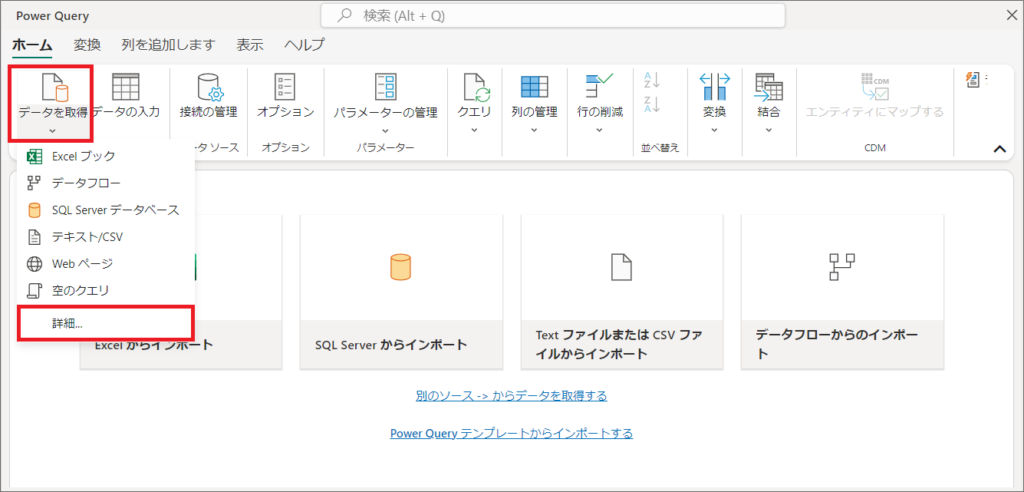
3.OneDriveのデータは「SharePointフォルダ」を指定して取得できます。
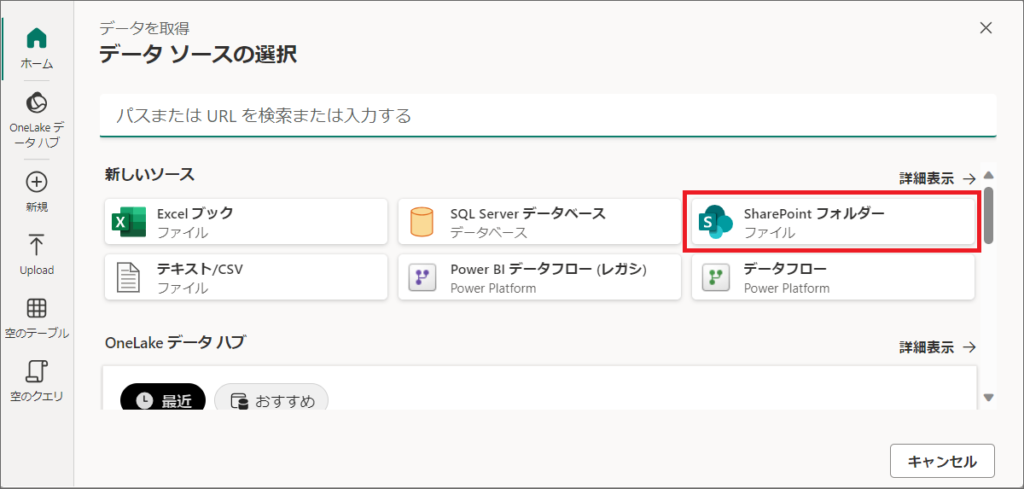
(Power Queryの操作は省略します)
4.Power Queryでデータ変換後、クエリをどこにデータを同期するか設定します。
今回は「レイクハウス」に同期するので、ギアアイコンから設定を確認します。
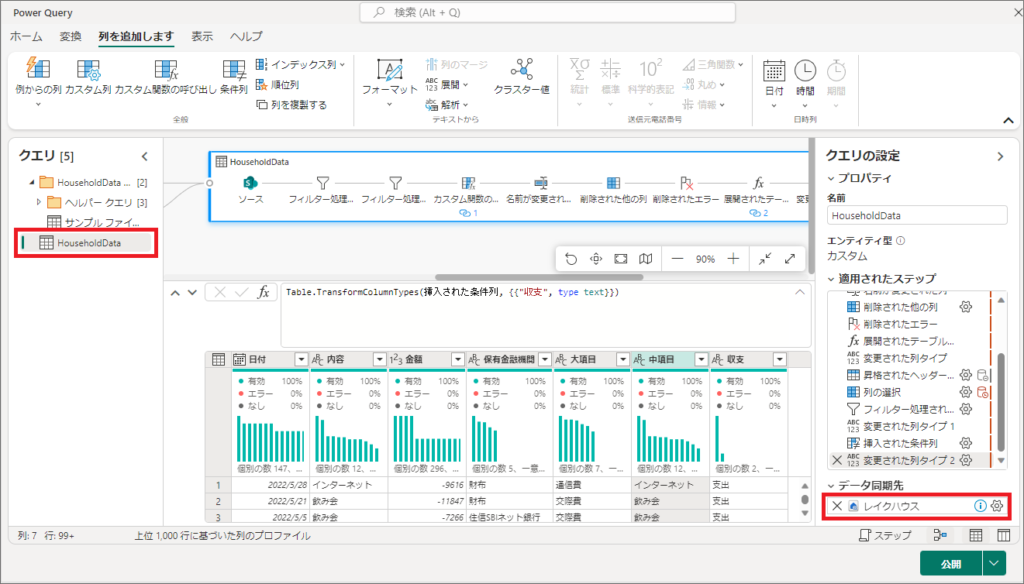
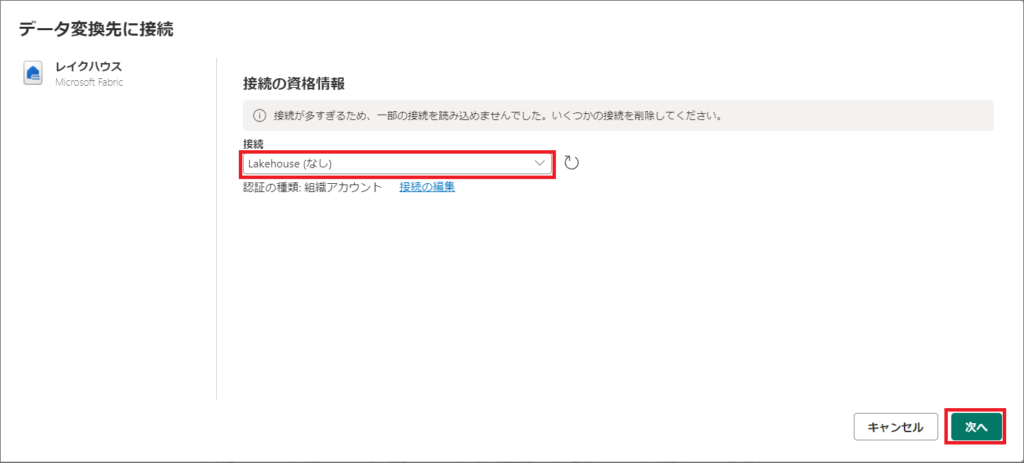
5.「Lakehouse」を選択し、次へをクリックします。
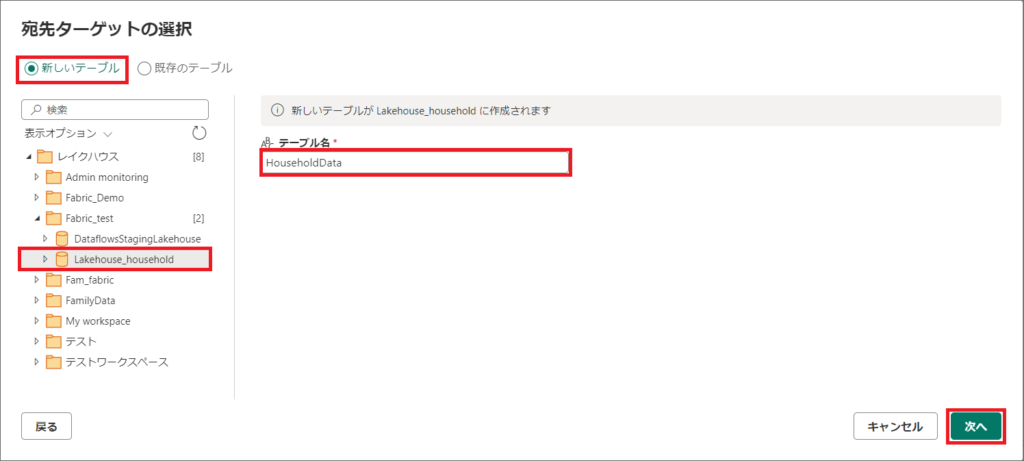
6.「新しいテーブル」を選択し、同期するワークスペース、レイクハウスを選択し、次へをクリックします。
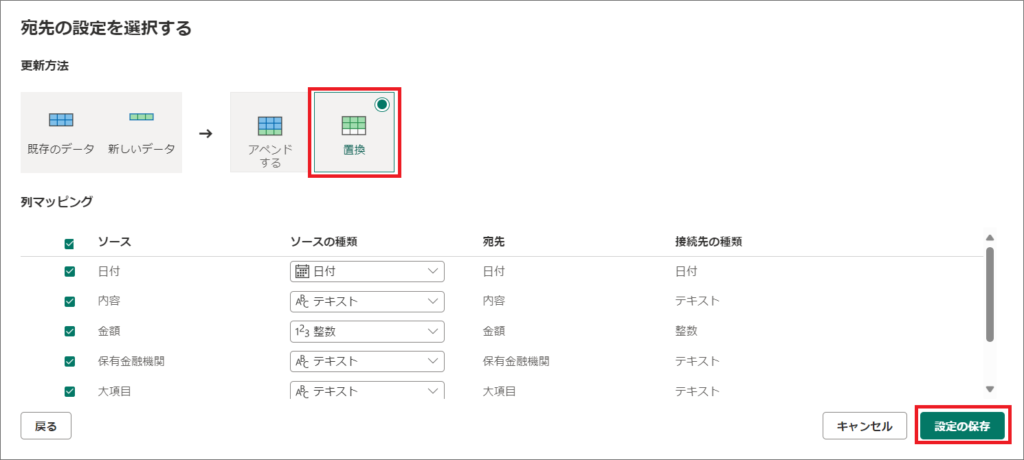
7.データを追加する場合は「アペンド」、データを置換する場合は「置換」を選択します。(今回は置換します)
8.列マッピングで適切なソース、データ型が設定されていることを確認し「設定の保存」をクリックします。
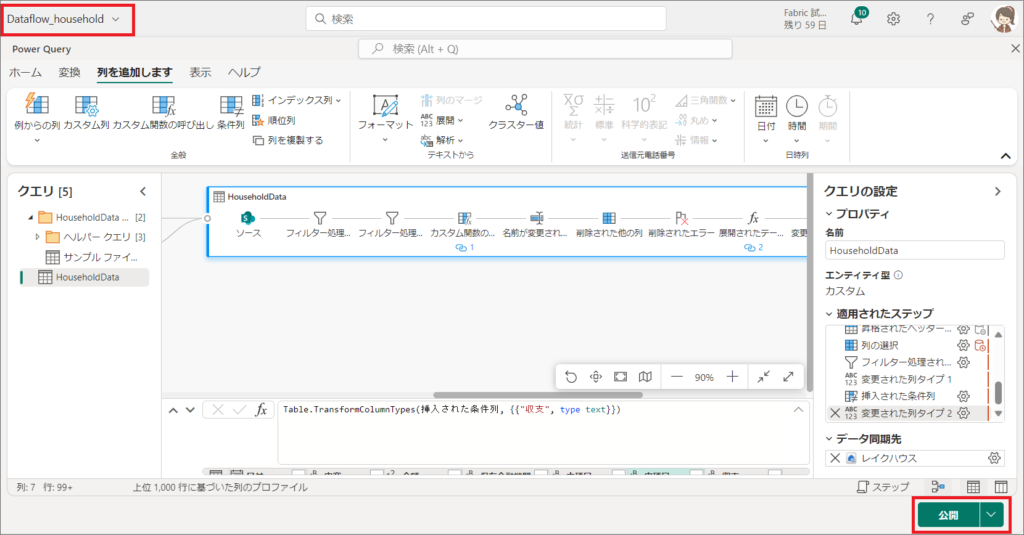
9.左上でDataflowの名称を変更して「公開」をクリックします。
10.しばらくデータフローの更新が走りますので、完了するまで待ちます。
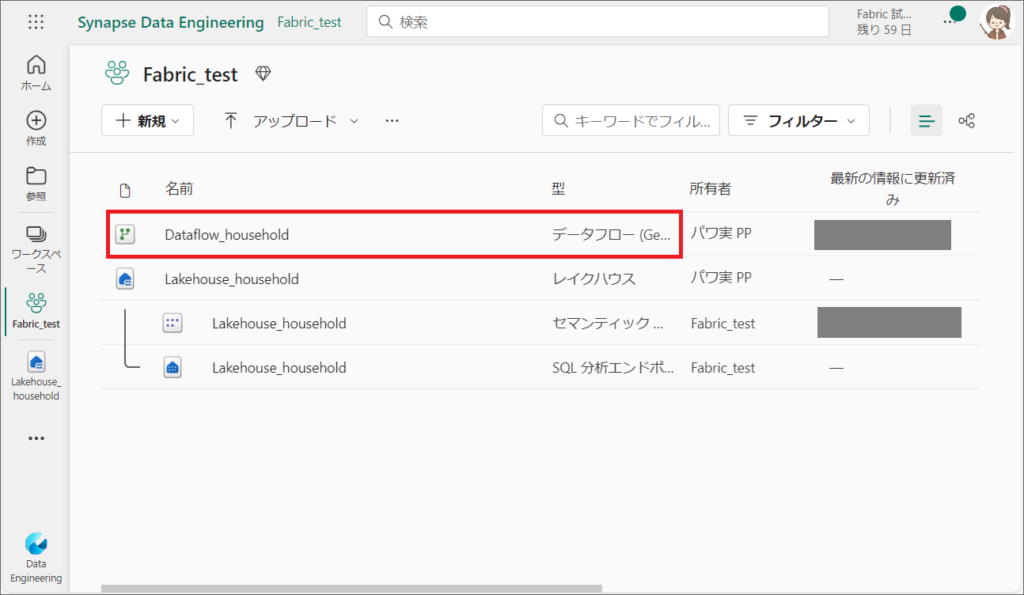
これで、データフローGen2もできました!
データファクトリー:パイプラインを作成
次に、データフロー(Gen2)を毎日決まった時間に自動実行し、失敗した場合は通知を出すための「パイプライン」を作成します。
パイプラインは、Data Engineeringからでも、Data Factoryからでも作成できます。
1.「Data Factory」を開きます。

2.「データパイプライン」をクリックし、任意の名前で作成してみます。
3.パイプラインが開いたら、「ホーム」タブから「データフロー」を選択します。
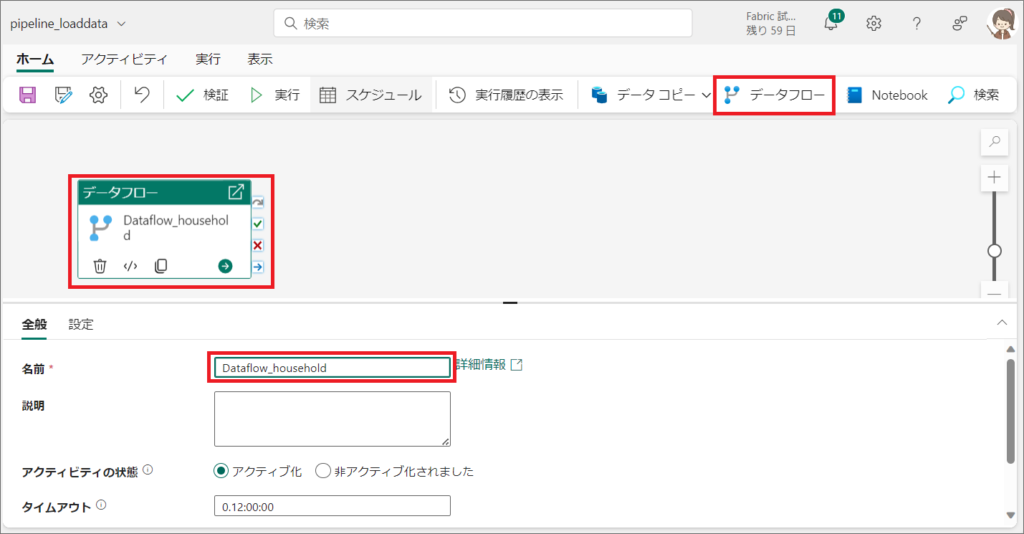
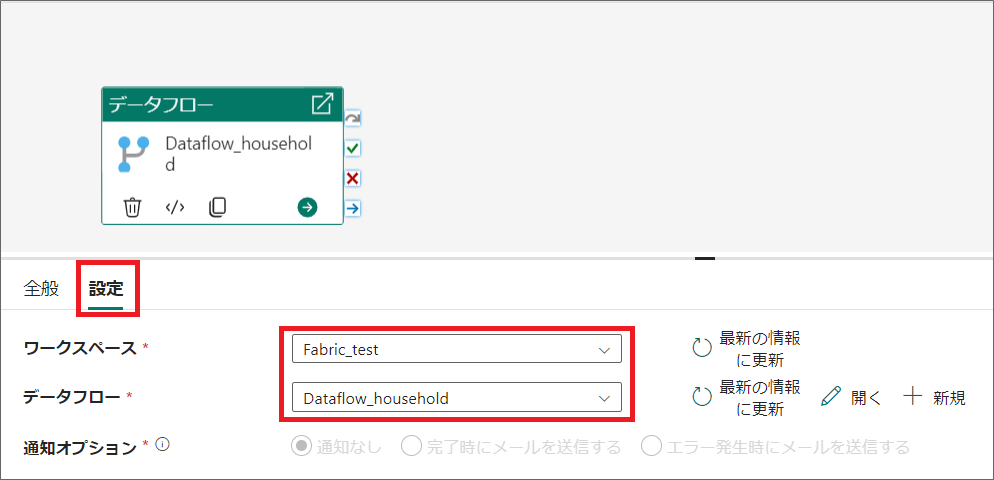
4.「全般」タブで、任意の名前を設定し、「設定」タブで、ワークスペースと、データフローを選択します。
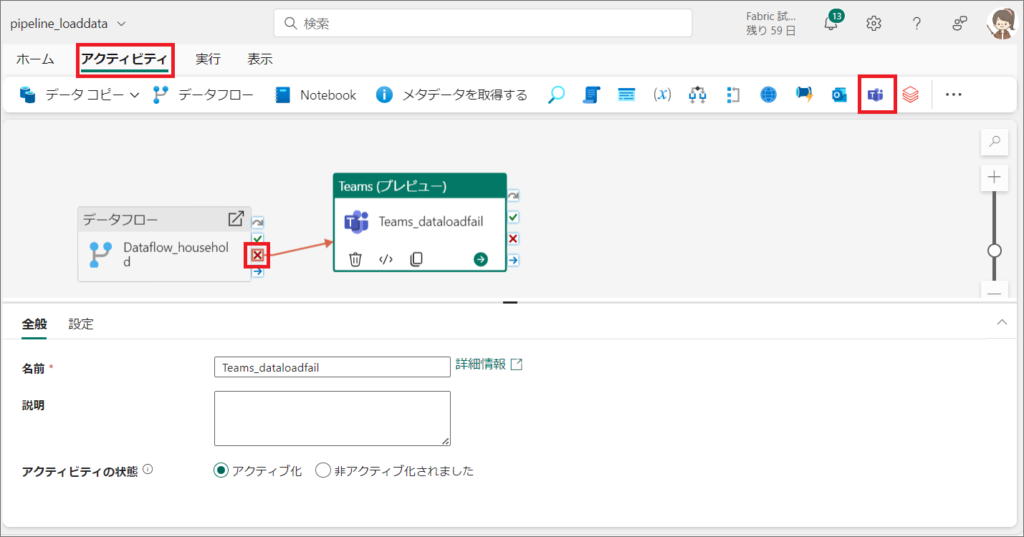
5.次に「アクティビティ」タブから、「Teams」を選択します。
6.先ほど作成した「データフロー」にカーソルを当て「失敗時(×アイコン)」から「Teams」にドラッグアンドドロップし、線をつなぎます。
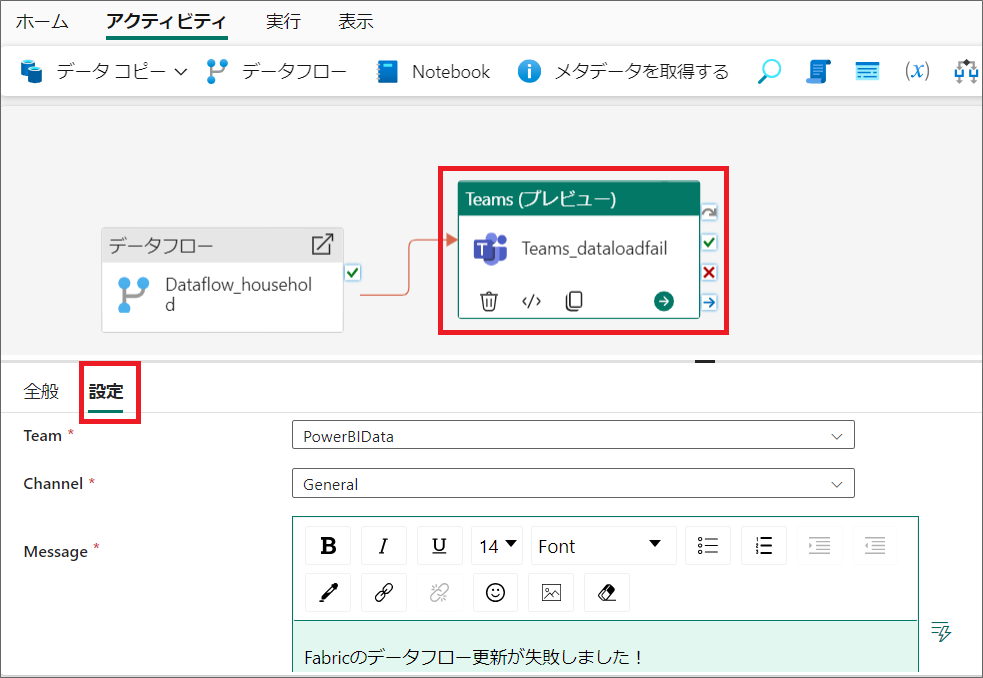
7.Teamsの「設定」では、通知するチーム、チャネル、タイトル、メッセージ等を設定できます。
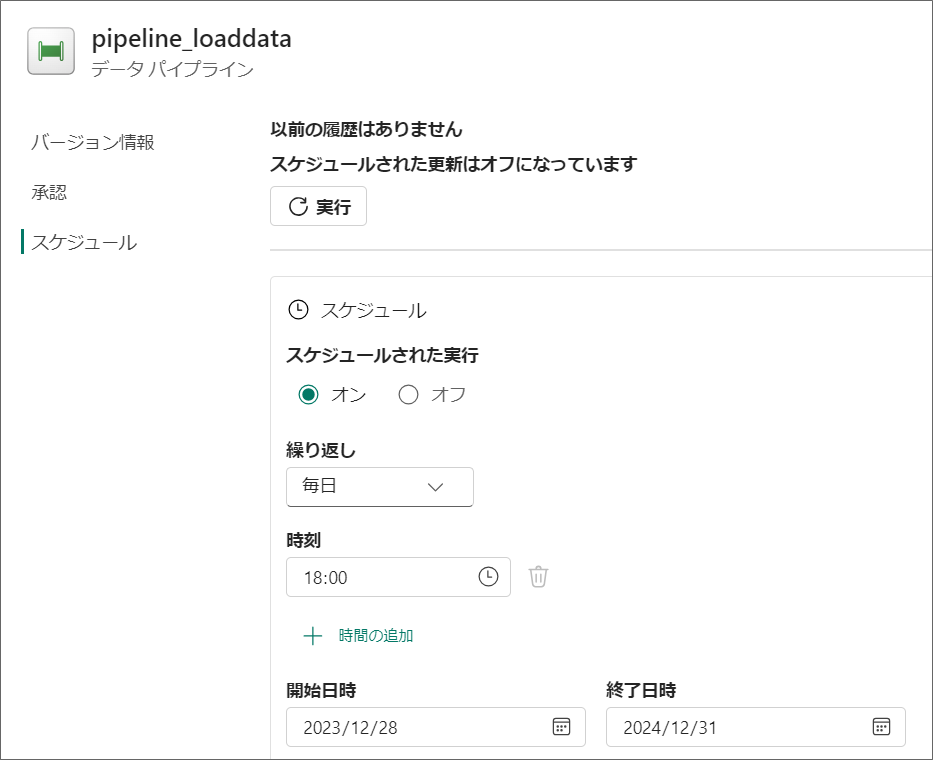
8.「ホーム」タブから「スケジュール」を選択し、繰り返し頻度や、時間等、スケジュール実行の設定をします。
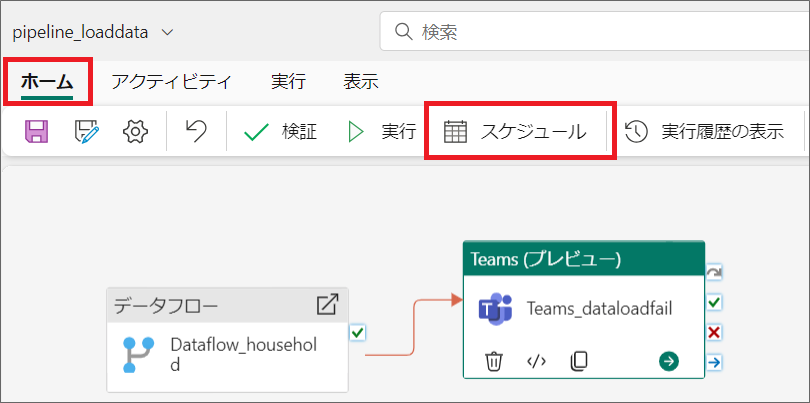
例えば毎日18時にパイプラインを実行する設定をしてみます。
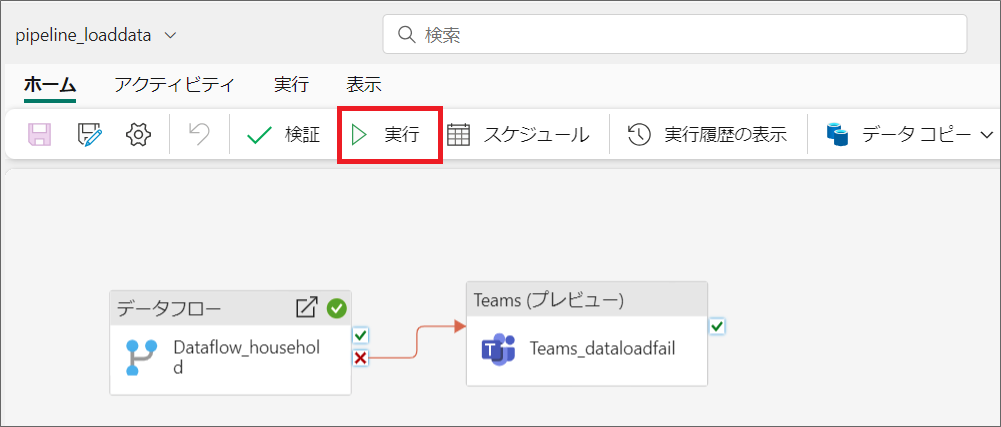
9.これでパイプラインの設定も完了したので、「保存」をクリックした後「実行」ボタンを押します。
10.しばらく待つと、アクティビティ(パイプラインの実行)が完了します。

11.ワークスペースに戻り、レイクハウスを確認してみます。
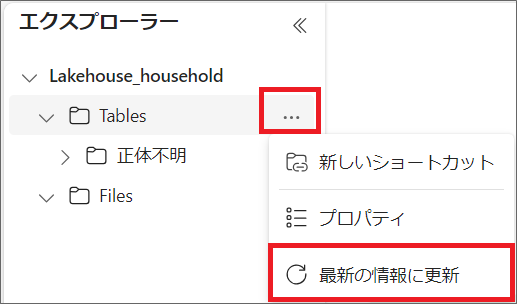
12.テーブルから「最新の情報に更新」をクリックします。
13.OneDriveのCSVから、データフローGen2を使って取得、データ変換した結果のテーブルが取り込まれています。
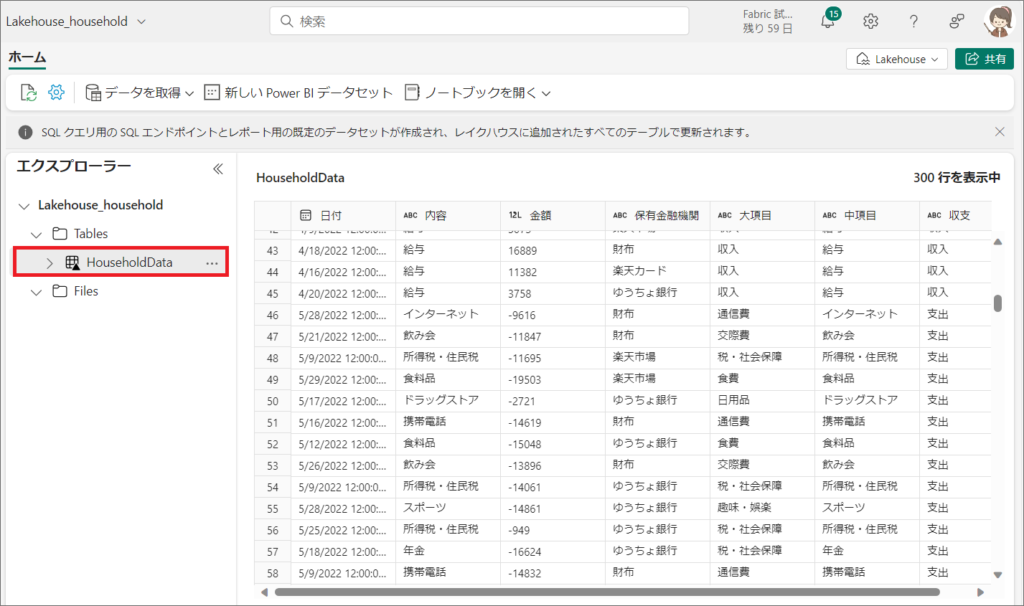
パイプラインは毎日18時に実行しているので、このテーブルは18時のパイプライン実行完了後に更新が反映されます。
Power BI:セマンティックモデル、レポートを作成
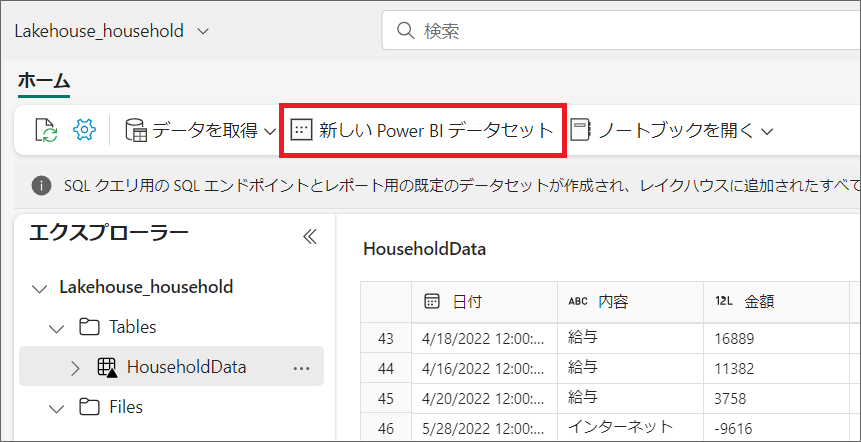
最後に「Power BI」で「レイクハウス」から「セマンティックモデル」を作成し、「Power BIレポート」を作ってみます。
1.レイクハウスに格納したデータから「新しいPower BI用のデータセット」を選択すると、セマンティックモデルを作成できます。
2.必要なテーブルを選択して「確認」をクリックします。
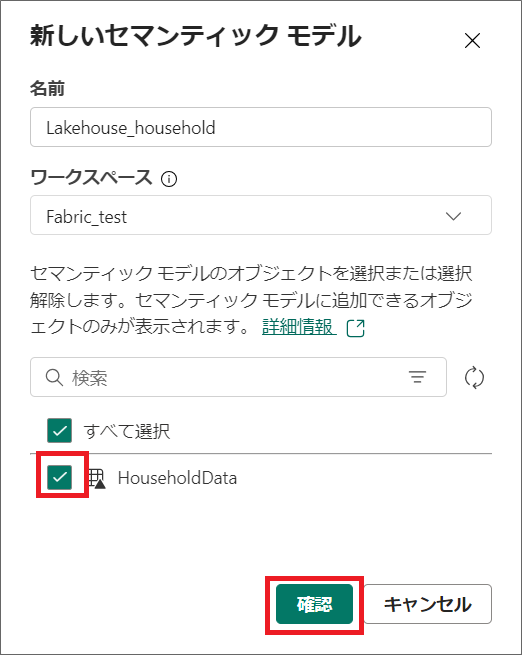
今回は1つのテーブルのみ取り込みましたが、複数テーブルを選択して、データモデルを構築することも可能です。
3.セマンティックモデルが開きます。
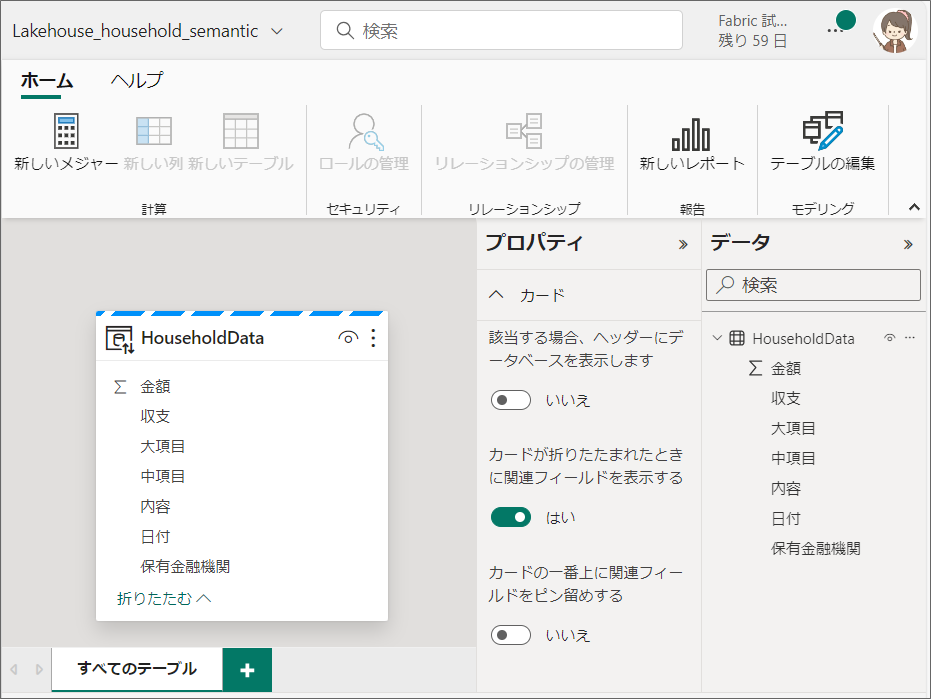
ここはPower BIデスクトップのモデルタブとほぼ同様で、リレーションシップの設定や、新しいメジャーの作成もできます。
後から、このセマンティックモデルを編集することもできます。
最後にセマンティックモデルからPower BIレポートを作成します。
4.ワークスペースに戻り「新規」からレポートを作成することもできますし、セマンティックモデルの三点リーダーから、「レポートを自動作成」等もできます。
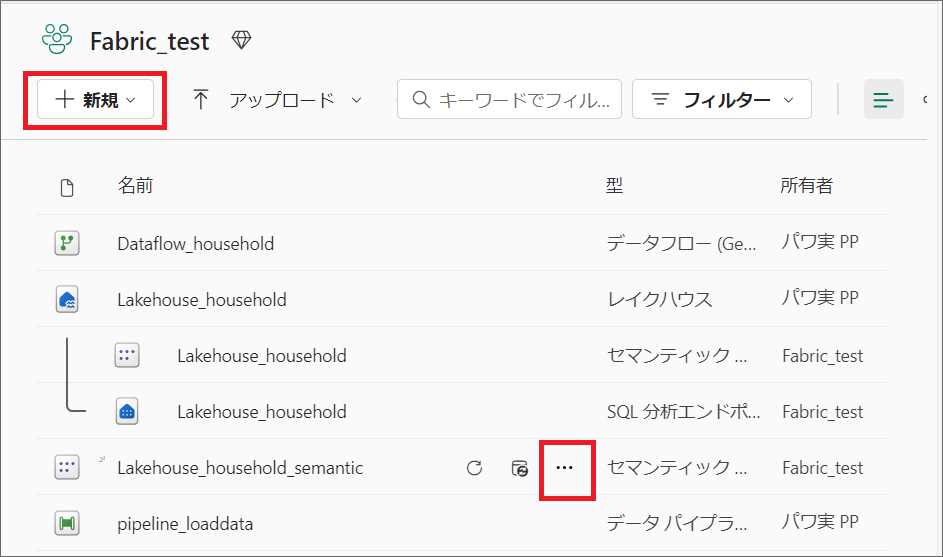
5.今回は試しに、セマンティックモデルの三点リーダーから「レポートの自動作成」をしてみます。
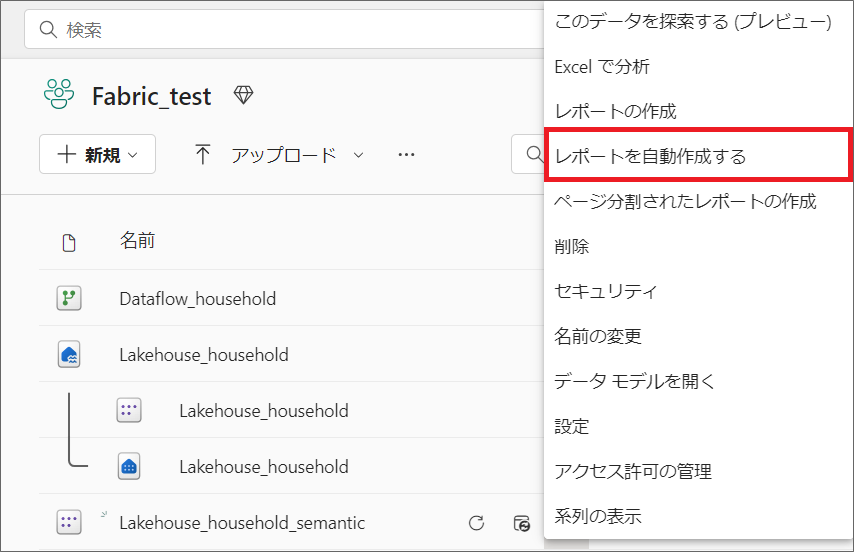
6.少し待つと、このようにPower BIレポートが自動作成されます。
修正したい場合は「編集」からレポートを変更します。
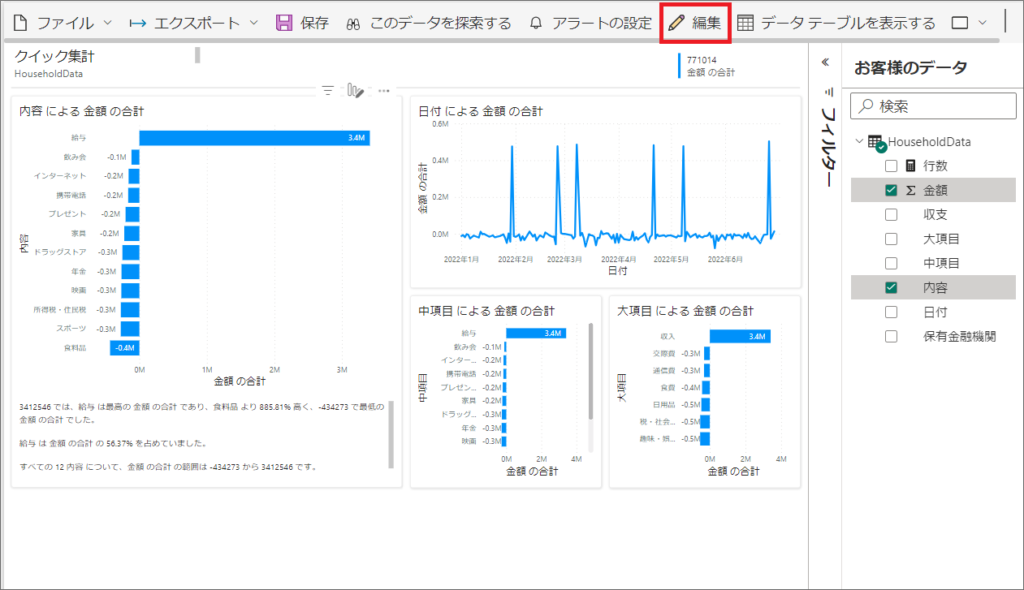
この操作は「Power BIデスクトップ」の「レポート」タブとほぼ同様です。
7.以下のような感じでPower BIレポートまで作成できました!
このような感じで、Microsoft Fabricを使って、OneDriveの家計簿データを取得し、Power BIレポートを作成できました!
この程度のデータ量であれば、Fabricを使う必要はありませんが、もっと大規模なデータ分析をする場合等には、Fabricが便利そうです。
最後に
本日は、Microsoft Fabricについて簡単に紹介し、Fabricを使ったPower BIレポート作成を試してみました。
Microsoft Fabricを使うと、あらゆる企業データを統合し、ビッグデータ分析、機械学習、リアルタイムデータ監視等が、SaaSサービス上で可能です。
データストアは、データウェアハウス、レイクハウス、Power BI データマート、KQLデータベースがあり、データ量や、データの種類、目的に応じて選択します。








